内功修炼-CPU缓存基础与CPU性能优化
在计算的前几十年中,主内存非常慢且昂贵得令人难以置信,但是CPU也不是特别快。从1980年代开始,差距开始迅速扩大。微处理器的时钟速度飞速发展,但是内存访问时间的改善远没有那么明显。随着这种差距的扩大,越来越明显的是需要一种新型的快速存储器来弥合这种差距。
1980及以前:cpu没有cache
1980~1995: cpu开始有2级缓存
至今:有过L4,有些有L0,普遍有L1、L2、L3
CPU缓存基础知识
寄存器(Register)是中央处理器内用来暂存指令、数据和地址的电脑存储器。寄存器的存贮容量有限,读写速度非常快。在计算机体系结构里,寄存器存储在已知时间点所作计算的中间结果,通过快速地访问数据来加速计算机程序的运行。
寄存器位于存储器层次结构的最顶端,也是CPU可以读写的最快的存储器。
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
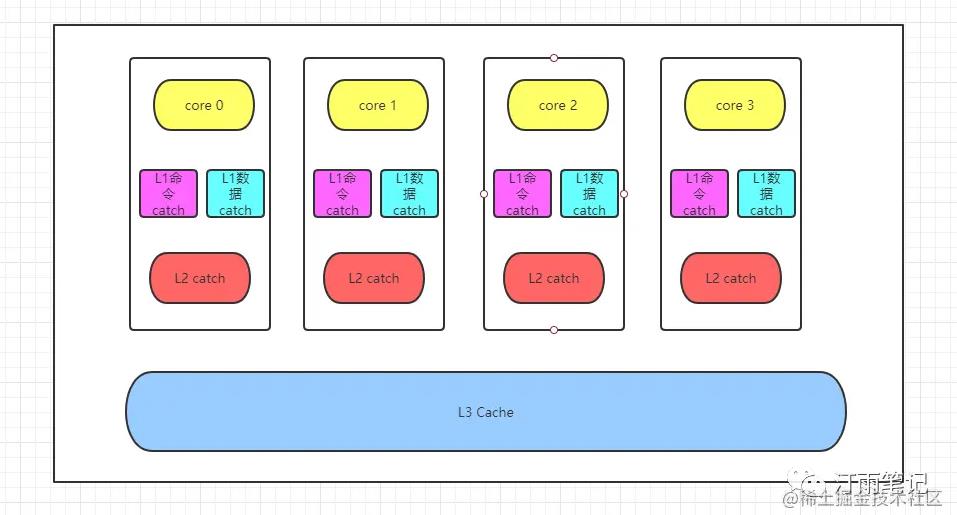
- L1缓分成两种,一种是
指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。 - L1和L2缓存在每一个CPU核中,
L3则是所有CPU核心共享的缓存。 - L1、L2、L3的越离CPU近就越小,速度也越快,越离CPU远,速度也越慢。
- 再往后面就是内存,内存的后面就是硬盘
| 到CPU | 需要CPU周期 | 需要的时间 |
|---|---|---|
| RAM内存 | 大约107 | 大约27-36ns |
| QPI总线传输 | - | 大约20ns |
| L3 cache | 大约40-45 | 大约10ns |
| L2 cache | 大约10 | 大约3ns |
| L1 cache | 大约3-4 | 大约1ns |
| 寄存器 | 大约1 | - |
CPU缓存命中
缓存行(Cache Line)也叫缓存块,就是说cpu加载数据是一块一块加载的。一般来说,一个cache line最小加载的数据是64Bytes=16个32位的整型(也有其他cpu32Bytes和128Bytes的)
当从内存中取单元到cache中时,会一次取一个cacheline大小的内存区域到cache中,然后存进相应的cacheline中。
例如:我们要取地址 (t, s, b) 内存单元,发生了cache miss,那么系统会取 (t, s, 00…000) 到 (t, s, FF…FFF)的内存单元,将其放入相应的cacheline中。
缓存块与内存之间的映射策略
假设: cache共10缓存行, 内存1000个缓存行大小
缓存与内存的映射策略可分为:
直接映射, 内存的0,10,20...只能缓存到cache的0位置,1,11,21...只能缓存到cache1位置等等。全相联映射, 内存的所有位置能缓存到cache的任意位置。组相联映射, 将cache的10个缓存行分成2组,每组5缓存行, 内存也每5个缓存行进行分组, 第0,2,4...只能缓存到cache的第0组,1,3,5...只能缓存到cache的第1组等等。在每个组内使用全相联映射。也就是先分组, 对分组进行直接映射, 组内进行全相联映射。每个组有5个缓存行, 称为5路组相联cache。
其中直接映射硬件简单成本低,但灵活性差;全相联映射灵活性差,但成本高;组相联映射实际上是直接映射和全相联映射的折中方案。这只介绍组相联映射。
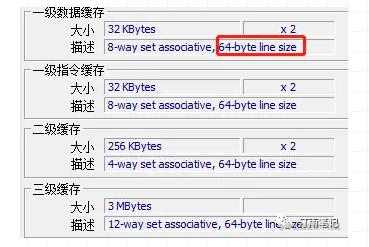
上图是一个CPU的缓存, 其中L1 cache的大小是32K Bytes,8-way set associative(8路组相连, 也就是每组有8个cache line),一个缓存块64 Bytes,总共有32K/64=512个缓存块, 512/8=64组。
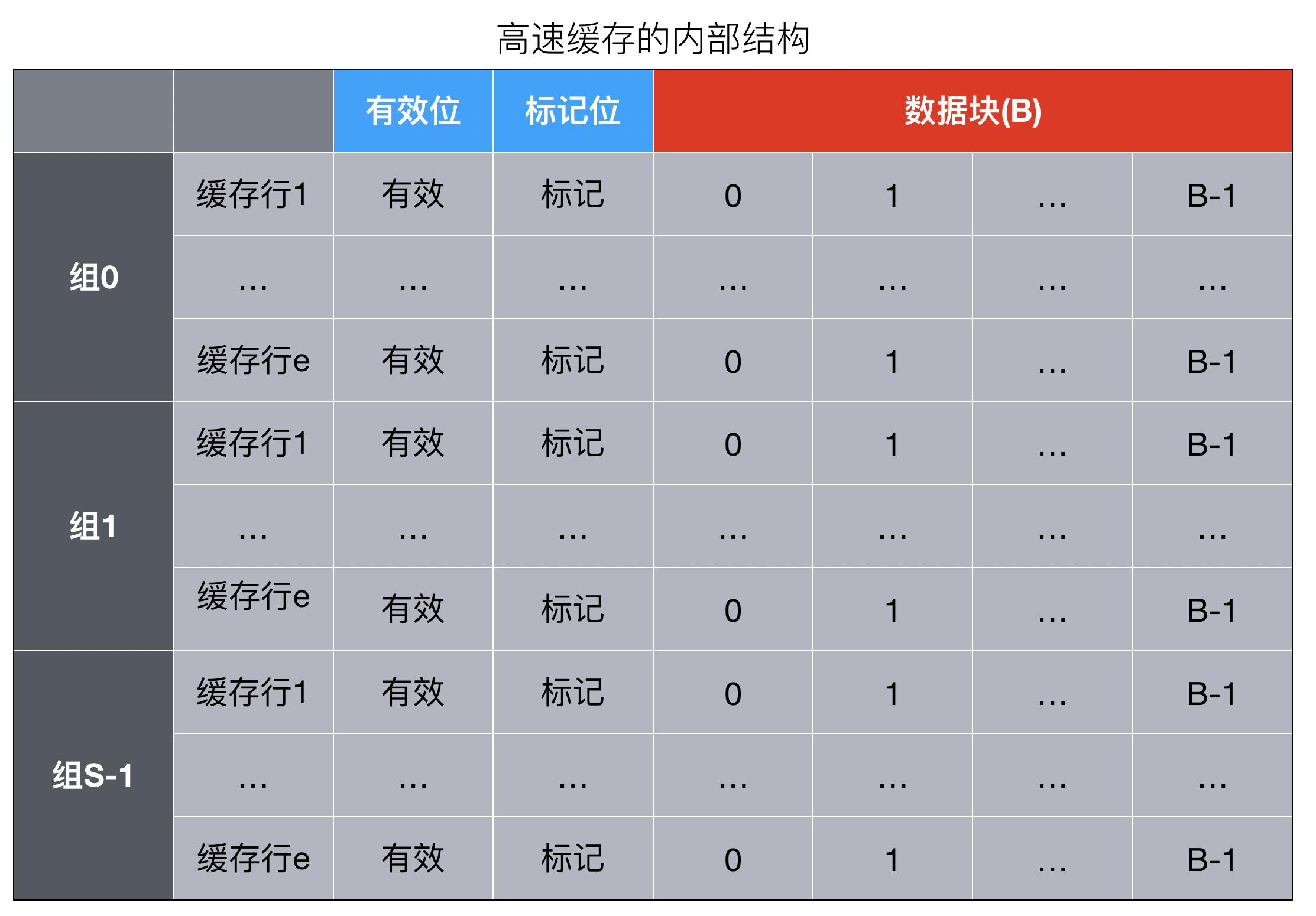
- 高速缓存的组成由
S个高速缓存组(cache set ) - 每一组包含
E个高速缓存行( cache line), - 每一行由一个
有效位(valid bit)指明这个行是否包含有意义的信息;一个长度为t的标记位(tag bit),唯一标识存储在这个高速缓存行中的块在内存中的地址;和一个B字节的数据块(block)构成,也是最小的寻址单元 - 高速缓存的结构可以用元组
(S,E,B,m)来描述。
缓存寻址
当从缓存中获取一个数据时,如果缓存行中存在该数据的有效副本,称为缓存命中,否则称为缓存未命中。高速缓存确定一个请求是还命中, 要分为三步选择组、选择行、字抽取。里面的m表示有m位表示地址(主存物理地址数)

内存地址中的特定字节位在cache中的含义:
- t位
标记位tag,用来标识当前缓存行数据是还有效 - s个
组索引set index,用来定位所访问的地址在高速缓存中所属的组编号 - b个
偏移块位block offset,访问数据在缓存行中的数据块中块的偏移量
怎么寻址流程
- CPU取内存地址。
- 内存地址中,中间的
s位决定了该单元被映射到哪一组。 - 内存地址中,高
t位用来校验该组的cacheline是否是CPU要访问的内存单元。 - cacheline中
valid校验成功, 当tag和valid校验成功时,我们称为cache命中。最低的b位决定了该单元在cacheline中的偏移量,取出单元并放入CPU寄存器中即可。 - 校验失败说明并不在cache中, 系统就会从内存中取得该单元,将其装入cache中,与此同时也放入CPU寄存器中,等待下一步处理。
缓存一致性
多核CPU每个核心都有自己的缓存,当多个核心同时访问同一块共享数据时,就需要确保这些数据在各个核心的缓存中保持一致,以避免出现数据不一致的问题。
为了实现CPU缓存一致性,通常采用缓存一致性协议。这些协议定义了在不同核心之间如何传播数据更新的规则,以确保当一个核心更新了共享数据时,其他核心能够看到这些更新。其中,MESI协议是一种广泛使用的缓存一致性协议,它通过维护缓存行的状态来管理数据的一致性。
在MESI协议中,每个缓存行有4个状态,分别是:
- M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有)
- E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据
- S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝
- I(无效,Invalid):缓存行失效, 不能使用
状态改变:
- 初始:一开始时,缓存行没有加载任何数据,所以它处于 I 状态。
- 本地写(Local Write):如果本地处理器写数据至处于 I 状态的缓存行,则缓存行的状态变成 M。
- 本地读(Local Read):如果本地处理器读取处于I状态的缓存行,很明显此缓存没有数据给它。此时分两种情况:(1)其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成 E 状态,表示只有我一家有这条数据,其它处理器都没有 (2)其它处理器的缓存有此行数据,则将此缓存行的状态设为 S 状态。(备注:如果处于M状态的缓存行,再由本地处理器写入/读出,状态是不会改变的)
- 远程读(Remote Read):假设我们有两个处理器 c1 和 c2,如果 c2 需要读另外一个处理器 c1 的缓存行内容,c1 需要把它缓存行的内容通过内存控制器 (Memory Controller) 发送给 c2,c2 接到后将相应的缓存行状态设为 S。在设置之前,内存也得从总线上得到这份数据并保存。
- 远程写(Remote Write):其实确切地说不是远程写,而是c2得到c1的数据后,不是为了读,而是为了写。也算是本地写,只是 c1 也拥有这份数据的拷贝,这该怎么办呢?c2 将发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置I的过程将给写操作带来很大的性能消耗。
除了缓存一致性协议外,还有一些其他的机制可以帮助实现CPU缓存一致性,例如写直达和写回策略。
写直达策略在每次写操作时都会将数据同时写入内存和缓存,以确保数据的一致性。写回策略则只在必要时才将数据写回内存,这通常发生在缓存行被替换或者显式地清空缓存时。
伪共享问题
假设有两个线程(Thread1和Thread2)并且定义了两个变量a,b且两个变量在同一个cache line中,Thread1修改a的同时Thread2修改b,在a变量被修改时,导致Thread2的cache line失效,需将Thread1的此cache line回写到内存后同步到Thread2的对应cache line中。同时Thread2修改b后Thread1的cache line也需要再同步给Thread1。导致性能极大浪费。
解决伪共享的办法
解决伪共享的办法主要就是让数据不在同一个cache line中,而一个缓存行一般64byte数据。在c#中有很多种方法,这里只列举一部分:
数据对齐(Padding):通过在数据结构中添加填充字段,确保相关数据不会位于同一缓存行上。这可以通过显式地在字段之间添加long或int数组来实现,或者使用特定的库和工具来自动进行填充。数据重排(Data Reordering):重新组织数据结构,将经常由不同线程访问的字段分开,以减少它们位于同一缓存行的可能性。线程局部存储(Thread Local Storage, TLS):ThreadLocal类,对于每个线程,分配其自己的数据副本,这样就不会发生缓存行竞争。但是,这种方法可能会增加内存消耗,并需要额外的同步来保持数据一致性。 使用volatile关键字:volatile关键字可以确保变量在多个线程之间的可见性,避免编译器对代码进行优化。使用volatile修饰共享变量可以防止伪共享的问题。使用StructLayout属性:在C#中,你可以使用[StructLayout(LayoutKind.Explicit)]属性来控制值类型的布局。通过设置LayoutKind.Sequential或LayoutKind.Explicit,可以明确指定结构体成员的顺序或对齐方式,有助于减少伪共享的可能性。
请注意,伪共享是一个复杂的问题,没有单一的解决方案适用于所有情况。通常需要根据应用程序的具体需求和部署环境来定制解决方案。
代码中应用
演示伪共享
using System.Diagnostics;
namespace abc
{
public class Ddd
{
static void Main()
{
// 单线程
int[] arrayint1 = new int[100];
Stopwatch swMinute1 = new();
swMinute1.Start();
Task task11 = Task.Run(() =>
{
for (int i = 0; i < 100000000; i++)
{
arrayint1[0] += 1;
}
for (int i = 0; i < 100000000; i++)
{
arrayint1[1] += 1;
}
});
Task.WaitAll([task11]);
swMinute1.Stop();
Console.WriteLine($"单线程:总共执行时间{swMinute1.ElapsedMilliseconds}");
// 双线程
int[] arrayint = new int[100];
Stopwatch swMinute = new();
swMinute.Start();
Task task1 = Task.Run(() =>
{
for (int i = 0; i < 100000000; i++)
{
arrayint[0] += 1;
}
});
Task task2 = Task.Run(() =>
{
for (int i = 0; i < 100000000; i++)
{
arrayint[1] += 1;
}
});
Task.WaitAll([task1, task2]);
swMinute.Stop();
Console.WriteLine($"双线程:总共执行时间{swMinute.ElapsedMilliseconds}");
Console.ReadKey();
}
}
}
// 以上代码打印结果:
// 单线程:总共执行时间328
// 双线程:总共执行时间600
// 注意,这里的多线程执行效率还比不上单线程
// 如果将代码换成 arrayint[99] += 1; arrayint1[99] += 1; 打印结果:
// 单线程:总共执行时间327
// 双线程:总共执行时间290
// 注意, 这里双线程效率比单线程效率提升了一些避免伪共享
// 数据对齐(Padding)用 _padding1-7这56个Byte去填充64个字节,确保Value在同一个缓存行 中
public struct PaddedLong
{
public long Value;
private long _padding1, _padding2, _padding3, _padding4, _padding5, _padding6, _padding7;
}
// 使用ThreadLocal<T>类
public class Program
{
private ThreadLocal<int> sharedVariable = new ThreadLocal<int>();
// 线程1修改sharedVariable的值
private void Thread1()
{
sharedVariable.Value = 1;
}
// 线程2读取sharedVariable的值
private void Thread2()
{
int value = sharedVariable.Value;
}
}
// 指定结构体的布局方式为显式定义
[StructLayout(LayoutKind.Explicit)]
public struct MyStruct
{
// 定义一个单独的缓存行,用于分离共享的字段
[FieldOffset(0)]
public long Field1;
// 添加一些无关的字段,使得Field2与其他字段分配在不同的缓存行中
[FieldOffset(64)]
public byte Padding1;
[FieldOffset(128)]
public byte Padding2;
[FieldOffset(192)]
public byte Padding3;
// 定义另一个单独的缓存行,用于分离共享的字段
[FieldOffset(256)]
public long Field2;
}
// 使用volatile关键字
public class Program
{
private volatile int sharedVariable;
// 线程1修改sharedVariable的值
private void Thread1()
{
sharedVariable = 1;
}
// 线程2读取sharedVariable的值
private void Thread2()
{
int value = sharedVariable;
}
}扩展阅读
干货,肝了一周的CPU缓存基础
性能优化-CPU篇
速度优化:CPU 优化(上)
速度优化:CPU 优化(下)
聊聊CacheLine
Cache的基本原理(直接映射、组相联、全相联)
最后更新于 2024-01-13 13:51:08 并被添加「」标签,已有 3860 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭