分布式ID生成器
需求背景
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求。此时一个能够生成全局唯一ID的系统是非常必要的。
特点
- 全局唯一,不能出现重复。
- 高性能,分布式系统中通常每秒会有很多数据产生。
- 单调递增,保证下一个ID一定大于上一个ID,这样可以保证某些索引快速建立。例如B-tree结构的索引,某些排序需求等。
- 安全性,不能透露关键业务信息,例如每日订单量。可反解开后可获得一些有用信息,比如时间。
- 可扩展,业务增长导致id生成器不够用时,有扩展的空间。重新升级后,旧的id可以升级成新id。
- 数据路由,可由id逆推数据所在的服务器、数据库、数据表。
常见算法
UUID
优点:本地生成ID,不需要进行远程调用,时延低,性能高;
缺点:没有排序,无法保证趋势递增;UUID往往是使用字符串存储,查询的效率比较低;存储空间比较大;ID本事无业务含义,不可读;
snowflake雪花算法,及其变种
优点:本地生成性能高;时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增;灵活度高,可以根据业务需求,调整bit位的划分,满足不同的需求;
缺点:依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成,在分布式场景中,服务器时钟回拨会经常遇到,一般存在10ms之间的回拨;小伙伴们就说这点10ms,很短可以不考虑吧。但此算法就是建立在毫秒级别的生成方案,一旦回拨,就很有可能存在重复ID。
实践注意:比如前端数字类型最多53位,你一个json以long的形式传到前端基本上就掉坑了。
号段模式
号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。
号段模式有个缺点,在没有把内存中的ID消费完前,如果重启服务,则可能会导致一部分id作废,不过这对于大部分业务都是可接受的。
Redis生成方案
利用redis的incr原子性操作自增
MongoDB的objectid
自带的,这个就不多说.
ZooKeeper生成ID
实现方式有两种,一种通过节点,一种通过节点的版本号,这了不多说。
SnowFlake(雪花)算法
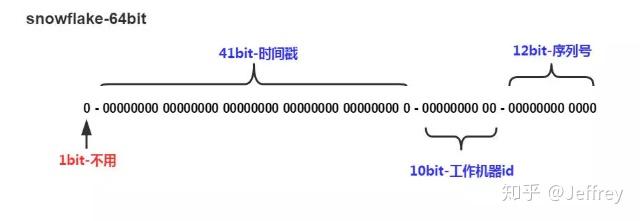
组成部分(64bit)
1.第一位 占用1bit,其值始终是0,没有实际作用。
2.时间戳 占用41bit,精确到毫秒,总共可以容纳约69年的时间。
3.工作机器id 占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。
4.序列号 占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢:: 同一毫秒的ID数量 = 1024 X 4096 = 4194304
雪花算法的实现
最后更新于 2021-12-09 17:59:56 并被添加「」标签,已有 1766 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭