PerfView 是一种用于快速轻松地收集和查看时间和内存性能数据的工具。PerfView 使用操作系统的 Windows 事件跟踪 (ETW) 功能,该功能可以收集各种有用事件的信息,如高级收集部分所述。ETW 是 Windows 性能组几乎专门用于跟踪和了解 Windows 性能的强大技术,也是其 Xperf 工具的基础。PerfView 可以被认为是该工具的简化和用户友好版本。此外,PerfView 还能够收集 .NET GC 堆信息以执行内存调查(即使对于非常大的 GC 堆)。PerfView 解码 .NET 符号信息以及 GC 堆的能力使 PerfView 成为托管代码调查的理想选择。
部署和使用 PerfView
PerfView 旨在易于部署和使用。若要部署 PerfView,只需将 PerfView.exe 复制到要使用它的计算机即可。不需要其他文件或安装步骤。PerfView 功能是“可自行发现的”。初始显示是一个“快速入门”指南,引导您收集和查看您的第一组配置文件数据。还有一个内置教程。将鼠标悬停在大多数 GUI 控件上将为您提供简短的说明,超链接会将您带到本用户指南中最合适的部分。最后,PerfView 是“启用右键单击”的,这意味着你想以某种方式操作数据,右键单击可以让你发现 PerfView 可以为你做什么。
PerfView 是 V4.6.2 .NET 应用程序。 因此,您需要在实际运行 PerfView 的计算机上安装 V4.6.2 .NET 运行时。 在 Windows 10 和 Windows Server 2016 上,具有 .NET V4.6.2。在其他受支持的操作系统上,可以从独立安装程序安装 .NET 4.6.2。Win2K3 或 WinXP 不支持 PerfView。 虽然 PerfView 本身需要 V4.6.2 运行时,但它可以收集有关使用 V2.0 和 v4.0 运行时的进程的数据。在未安装 V4.6.2 或更高版本的 .NET 运行时的计算机上,还可以使用其他工具(例如 XPERF 或 PerfMonitor)收集 ETL 数据,然后将数据文件复制到具有 V4.6.2 的计算机上,并使用 PerfView 查看它。
PerfView 旨在收集和分析时间和内存方案。
另请参阅 PerfView 参考指南。
希望该文档在回答有关 PerfView 和一般性能调查的最常见问题方面做得相当好。如果您有任何疑问,您当然应该首先搜索用户指南以获取信息
然而,不可避免地,会有一些文档没有回答的问题,或者你想要拥有但尚不存在的功能,或者你想报告的错误。PerfView 是一个 GitHub 开源项目,你应该在
如果您只是问一个问题,您可以使用一个名为“问题”的标签来表示这一点。如果这是一个错误,如果您提供足够的信息来重现该错误,它确实会有所帮助。通常,这包括您正在操作的数据文件。您可以将小文件拖到问题本身中,但更有可能的是,您需要将数据文件放在云中的某个位置并在问题中引用它。最后,如果你提出建议,你越具体越好。除非您自己帮助实现,否则大型功能实现的可能性要小得多。请记住这一点。
可以通过转到 PerfView GitHub 下载页来获取最新版本的 PerfView
另请参阅 GC 堆内存调查教程
也许最好的入门方法是简单地尝试教程示例。在 Windows 7 上,建议您按照帮助提示中的说明编写帮助文档。PerfView 附带了两个“内置”教程示例。此外,我们强烈建议您编写的任何应用程序都具有性能计划,如 尽早和经常测量性能的第 1 部分和第 2 部分所述。
要运行“教程”示例,请执行以下操作:
还可以通过在命令行中键入“PerfView run tutorial”来运行教程示例。有关详细信息,请参阅从命令行收集数据。
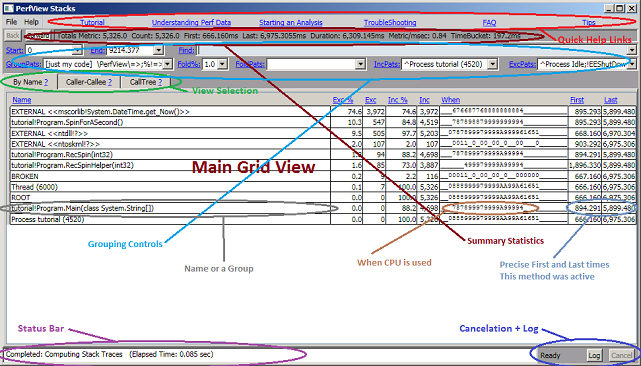
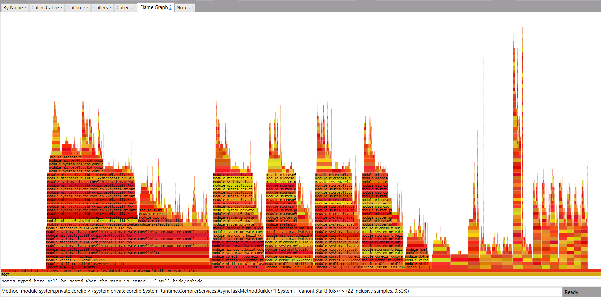
选择“Tutorial.exe”作为感兴趣的进程后,PerfView 会显示堆栈查看器,如下所示:
此视图显示 CPU 时间花费的位置。PerfView 对每个处理器的位置(包括整个堆栈)和每毫秒(请参阅了解性能数据)进行了采样,堆栈查看器显示这些示例。因为我们告诉 PerfView,我们只对 Tutorial.exe 过程感兴趣,所以此视图已被“IncPats”限制为仅显示该过程中使用的示例。
最好通过查看视图顶部的摘要信息来开始调查。这样一来,您就可以确认大部分性能问题确实与 CPU 使用率有关,然后再准确查找 CPU 的使用情况。这就是汇总统计数据的用途。我们看到,该过程花费了 84% 的挂钟时间消耗 CPU,这值得进一步研究。接下来,我们只需查看程序中“Main”方法的“When”列。此列显示 CPU 在收集时间间隔内如何用于该方法(或其调用的任何方法)。时间被分解为 32 个“TimeBucket”(在本例中,我们从汇总统计信息中看到,每个存储桶的长度为 197 毫秒),数字或字母表示 1 个 CPU 的使用百分比。9s 和 As 意味着您接近 100%,我们可以看到,在 main 方法的生命周期中,我们大部分时间都接近 100% 利用 1 个 CPU。主程序之外的区域可能没有兴趣(它们处理运行时启动和进程启动前后的时间),因此我们可能希望“放大”到该区域。
您只对部分跟踪感兴趣是很常见的。例如,您可能只关心启动时间,或者从单击鼠标到显示菜单的时间。因此,放大通常是您首先要执行的操作之一。 放大实际上只是选择一个时间区域进行调查。时间区域显示在“开始”和“结束”文本框中。这些可以通过三种方式进行设置
尝试这些技术中的每一种。 例如,要“放大”主要方法,只需将鼠标拖动到“第一次”和“最后一次”时间上即可同时选择两者,右键单击并选择时间范围。 您可以点击“返回”按钮撤消您所做的任何更改,以便重新选择。 另请注意,每个文本框都会记住该框的最后几个值,因此您还可以通过选择下拉列表(框右侧的小向下数组)并选择所需的值来“返回”特定的过去值。
对于 GUI 应用程序,跟踪整个运行过程,然后“放大”到用户触发活动的点的情况并不少见。您可以通过切换到“CallTree”选项卡来执行此操作。这将向您显示从进程本身开始的 CPU。视图的第一行是“Process32 tutorial.exe”,是整个进程的 CPU 时间摘要。“when”列显示进程随时间推移的 CPU(32 个时间段)。在 GUI 应用程序中,会出现未使用 CPU 的停顿,然后是与用户操作相对应的 CPU 使用率激增。这些显示在“何时”列中的数字中。通过单击“何时”列中的单元格,选择一个范围,右键单击并选择 SetTimeRange(或 Alt-R),您可以放大这些“热点”之一(您可能需要多次放大)。现在,您已经专注于您感兴趣的内容(您可以通过查看在此期间调用的方法进行确认)。这是一种非常有用的技术。
对于托管应用程序,在开始调查之前,您始终希望放大 main 方法。 原因是,在收集配置文件数据时,在 Main 退出后,运行时会花费一些时间将符号信息转储到 ETW 日志。 这几乎从来都不有趣,你想在调查中忽略它。 放大 Main 方法将执行此操作。
右键单击,然后选择“查找符号”。查找符号后,它将变成
如果要执行非托管调查,则可能需要少量 DLL 的符号。常见的工作流是查看 byname 视图,在按住 Ctrl 键的同时,选择包含具有大量 CPU 时间但未解析符号的 dll 的所有单元格。然后右键单击 -> Lookup Symbols,PerfView 将批量查找它们。有关更多详细信息或查找符号失败,请参阅符号解析。
PerfView 从“ByName 视图”开始,用于执行自下而上的分析(另请参阅启动分析)。在此视图中,您可以看到示例中涉及的每个方法(方法中出现一个示例,或者调用具有示例的例程的方法)。示例可以是非独占的(发生在该方法中),也可以是非独占的(发生在该方法或该方法调用的任何方法中)。默认情况下,按名称视图根据方法的独占时间对方法进行排序(另请参阅列排序)。这显示了程序中“最热门”的方法。
通常,“自下而上”方法的问题在于程序中的“热门”方法是
在这两种情况下,您都不希望看到这些帮助程序例程,而是最低的“语义有趣”例程。 这就是 PerfView 强大的分组功能发挥作用的地方。 默认情况下,PerfView 按以下方式对示例进行分组
例如,ByName 视图中的第一行是
这是“条目组”的一个示例。“OTHER”是该组的名称和 mscorlib!System.DateTime.get_Now() 是进入组的调用方法。从那时起,该组内 get_Now() 调用的任何方法都不会显示,而是简单地将它们的时间累积到此节点中。实际上,这种分组表示“我不想看到不是我的代码的函数的内部工作,但我确实希望看到我用来调用该代码的公共方法。要让您了解此功能的有用性,只需将其关闭(通过清除“GroupPats”框中的值),然后查看数据即可。您将看到更多带有“get_Now”使用的内部函数名称的方法,这只会使您的分析更加困难。(您可以使用“后退”按钮快速恢复之前的组模式)。
另一个有助于“清理”自下而上视图的功能是折叠百分比功能。此功能将导致所有“小”调用树节点(小于给定的 %)自动折叠到其父节点中。同样,您可以通过清除文本框(这意味着没有折叠)来查看此功能的帮助程度。关闭该功能后,您将看到更多时间“少量”的条目。这些小条目往往只会增加“混乱”,使调查更加困难。
完成 (2) 的快速方法是添加模式 '!?' 。此模式表示折叠任何没有方法名称的节点。有关详细信息,请参阅 foldPats 文本框。这给我们留下了一个非常“干净”的函数视图,其中只有语义相关的节点。
回顾:所有这些时间选择、分组和折叠是干什么用的?
性能调查的第一阶段是形成一个“性能模型”,目标是将时间分配给语义相关的节点(程序员理解并可以做某事的事情)。 我们通过形成一个语义上有趣的组并为其分配节点来做到这一点,或者通过将节点折叠到现有的语义相关组中,或者(最常见的)利用大型组(模块和类)的入口点,作为方便的“预制”语义相关节点。 目标是将成本分组到相对较少(< 10)的语义相关条目中。这使您可以推断该成本是否合适(这是调查的第二阶段)。
剩下的一个节点是一个名为“BROKEN”的节点。这是一个特殊节点,表示其堆栈跟踪被确定为不完整,因此无法正确归因的样本。只要这个数字很小(<几个百分点),那么它就可以被简单地忽略。有关详细信息,请参阅损坏的堆栈。
PerfView 将非独占时间和独占时间显示为指标 (毫秒) 和百分比,因为两者都很有用。 百分比可以让您很好地了解节点的相对成本,但是绝对值很有用,因为它非常清楚地表示“时钟时间”(例如,300 个样本表示 300 毫秒的 CPU 时间)。 绝对值也很有用,因为当该值明显小于 10 时,它变得不可靠(当您只有少数样本时,它们可能是“纯偶然”发生的,因此不应依赖。
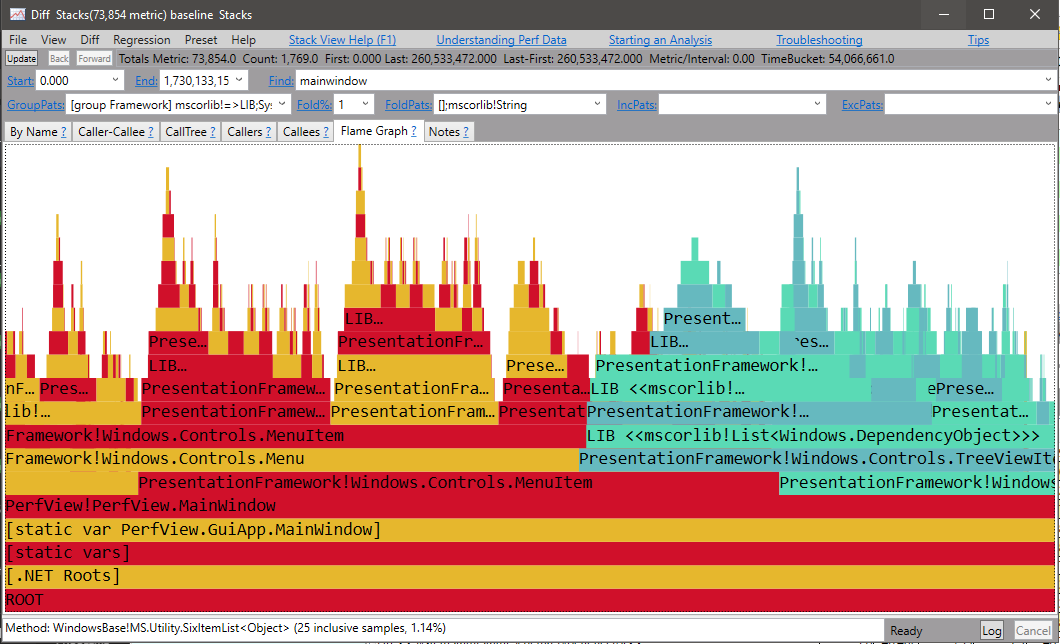
自下而上的视图在确定 get_Now() 方法和“SpinForASecond”消耗的时间最多方面做得非常出色,因此值得仔细研究。这符合我们对 Tutorial.cs 中源代码的期望。但是,了解自上而下消耗 CPU 时间的位置也很有用。这就是 CallTree 视图的用途。只需单击堆栈查看器的“CallTree”选项卡,即可进入该视图。最初,显示屏仅显示根节点,但您可以通过单击复选框(或按空格键)打开节点。这将扩展节点。只要一个节点只有一个子节点,子节点也会自动展开,以节省一些点击时间。您也可以右键单击并选择“展开全部”以展开所选节点下的所有节点。在根节点上执行此操作将产生以下显示
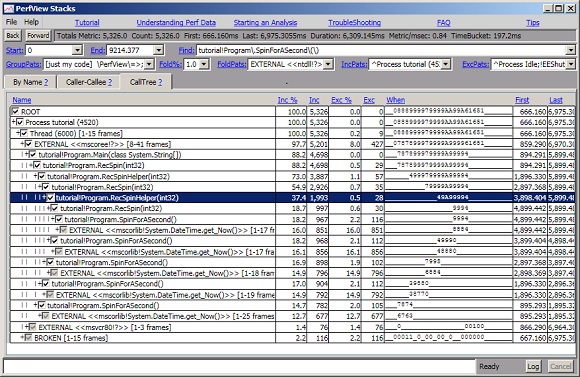
请注意,调用树视图是多么干净,没有很多“噪音”条目。 事实上,这种观点在描述正在发生的事情方面做得非常好。 请注意,它清楚地显示了 Main 调用 'RecSpin' 的事实,它运行 5 秒(从 894 毫秒到 5899 毫秒),同时消耗 4698 毫秒的 CPU(CPU 不是 5000 毫秒,因为实际收集配置文件的开销(以及其他不归因于此过程的操作系统开销以及损坏的堆栈), 通常在 5-10% 的范围内运行。 在这种情况下,它似乎约为 6%)。 “When”列还清楚地显示了 RecSpin 的一个实例如何运行 SpinForASecond(正好一秒钟),然后调用 RecSpinHelper,该实例在其余时间消耗接近 100% 的 CPU。. 呼叫树是一个精彩的自上而下的概要。
视图顶部的所有筛选和分组参数都会对任何视图(byname、caller-callee 或 CallTree)产生同等影响。 我们可以利用这一事实和“折叠%”功能来获得调用树“顶部”的更粗略视图。 展开所有节点后,只需右键单击窗口并选择“增加折叠百分比”(或更轻松地按 F7 键)。 这会将“折叠百分比”文本框的数量增加 1.6 倍。 通过反复按 F7 键,您可以不断修剪堆栈的“底部”,直到您只看到使用大量 CPU 时间的方法。 下图显示了按 F7 七次后的 CallTreeView。
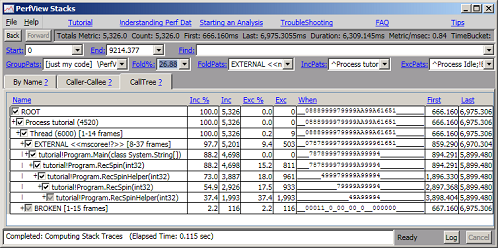
您可以使用“返回”按钮、Shift-F7 键(可降低折叠%)或只需在折叠百分比框中选择 1(例如从下拉菜单中)恢复上一个视图。
获取树的课程视图很有用,但有时您只想将注意力限制在单个节点上发生的情况上。 例如,如果 BROKEN 堆栈的包含时间很长,您可能希望查看“BROKEN”堆栈下的节点,以了解哪些样本在调用树中的正确位置“丢失”。 您可以通过在 Caller-callee 视图中查看 BROKEN 节点来轻松执行此操作。 为此,右键单击 BROKEN 节点,然后选择 Goto -> Caller-callee(或键入 Alt-C)。因为我们的跟踪中很少有样本是 BROKEN 的,所以这个节点不是很有趣。通过将 Fold % 设置为 0(空白),您可以获得以下视图
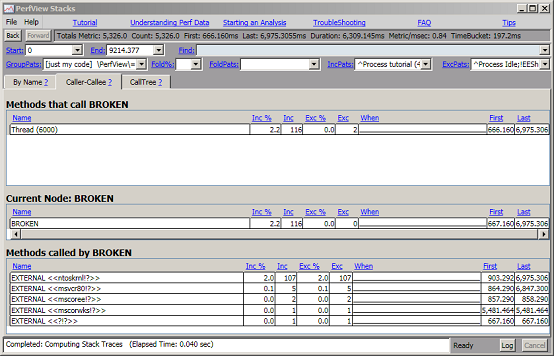
视图分为三个网格。中间部分显示“当前节点”,在本例中为“BROKEN”。顶部网格显示调用此焦点节点的所有节点。在 BROKEN 的情况下,节点仅在一个线程上。下图显示了按包含时间排序的“BROKEN”调用的所有节点。我们可以看到,大多数损坏的节点来自源自“ntoskrnl”dll(这是Windows操作系统内核)的堆栈,要深入研究,我们首先需要解析此DLL的符号。有关详细信息,请参阅符号分辨率。
虽然组是一个非常强大的功能,可以在“粗略”级别上理解程序的性能,但不可避免地,您希望“钻取”这些组并详细了解特定节点的细节。 例如,如果我们是负责 DateTime.get_Now() 的开发人员,我们就不会对它是从“SpinForASecond”例程调用的事实感兴趣,而是对里面发生的事情感兴趣。 此外,我们不希望看到来自程序其他部分的样本“混乱”了 get_Now() 的分析。 这就是“钻取”命令的用途。 如果我们返回“ByName”视图并右键单击“get_Now”,然后选择“Drill Into”,则会出现一个新窗口,其中仅提取了这些 3792 个样本。
最初,钻取不会更改任何筛选器/分组参数。 但是,现在我们已经分离了感兴趣的样本,我们可以自由地更改分组和折叠,以在新的抽象级别上理解数据。通常,这意味着取消对某些内容的分组。在本例中,我们想看看 mscorlib!get_Now() 是如何工作的,所以我们想看看 mscorlib 内部的细节。为此,我们选择“mscorlib!DateTime.get_Now() 节点,单击鼠标右键,然后选择“取消模块分组”。 这表明我们希望取消对“mscorlib”模块中的任何方法的分组。 这使您可以查看该例程的“内部结构”(无需完全取消分组) 结果是以下显示
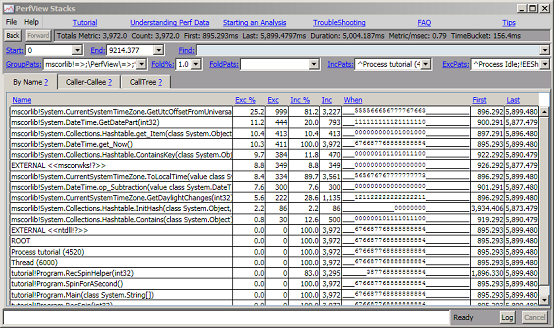
在这一点上,我们可以看到大部分“get_Now”时间都花在名为“GetUtcOffsetFromUniversalTime”和“GetDatePart”的函数中 我们可以使用堆栈查看器的全部功能,折叠、分组、使用 CallTree 或调用方-被调用方视图来进一步优化我们的分析。 由于“钻取”窗口与其父窗口是分开的,因此您可以将 is 视为“一次性”,并在查看完程序性能的这一方面后将其丢弃。
在上面的示例中,我们深入研究了方法的包容性样本。 但是,您也可以执行相同的操作来钻取独家示例。 当涉及用户回调或虚拟函数时,这很有用。 以具有内部帮助程序功能的“排序”例程为例。 在这种情况下,将那些属于节点“内部帮助程序”的样本(将折叠为“排序”的独占样本)与由用户“比较”函数引起的样本(通常不会分组为独占样本,因为它跨越了模块边界)会很有用。 通过钻取到“sort”的独占样本,然后取消分组,你只能看到“sort”中不属于用户回调的那些样本。 通常,这正是负责“排序”例程的程序员希望看到的。
一旦分析确定方法可能效率低下,下一步就是充分理解代码以进行改进。PerfView 通过实现“转到源”功能来帮助实现此目的。只需选择一个包含方法名称的单元格,右键单击并选择“转到源”(或使用 Alt-D(D 表示定义))。然后,PerfView 尝试查找源代码,如果成功,将启动文本编辑器窗口。例如,如果在“ByName”视图中选择“SpinForASecond”单元格,然后选择“转到源”,则会显示以下窗口。
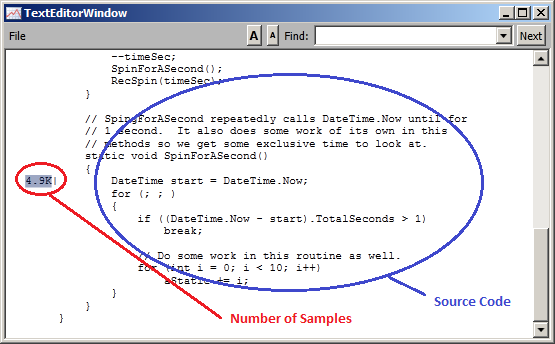
如您所见,将显示特定方法,并且每行都以该行所花费的成本(在本例中为 CPU MSec)为前缀。在此视图中,它显示 4.9 秒的 CPU 时间花在方法的第一行上。
遗憾的是,在 .NET 运行时 V4.5 之前,运行时没有向 ETL 文件发出足够的信息,无法将示例解析为行号(仅解析为方法)。因此,虽然 PerfView 可以调出源代码,但它无法准确地将示例放在特定行上,除非代码在 V4.5 或更高版本上运行。当 PerfView 没有所需的信息时,它只是将所有成本归因于方法的第一行。事实上,这就是您在上面的示例中看到的。如果在 V4.5 运行时上运行示例,则会得到更有趣的成本分布。本机代码不存在此问题(您将获得行级分辨率)。但是,即使在旧的运行时版本上,您至少也有一种简单的方法可以导航到相关源代码。
PerfView 通过查找与代码关联的 PDB 文件中的信息来查找源代码。因此,第一步是 PerfView 必须能够找到 PDB 文件。默认情况下,大多数工具会将 PDB 文件的完整路径放在它生成的 EXE 或 DLL 中,这意味着,如果尚未移动 PDB 文件(并且位于生成的计算机上),则 PerfView 将找到 PDB。然后,它会查找包含每个源文件的完整路径名的 PDB 文件,如果你在生成二进制文件的计算机上,则 PerfView 将查找源文件。因此,如果你在你构建的同一台机器上运行,它就会“正常工作”。
但是,通常不会在生成的计算机上运行,在这种情况下,PerfView 需要帮助。PerfView 遵循用于查找源代码的其他工具的标准约定。具体而言,如果 _NT_SYMBOL_PATH 变量设置为以分号分隔的路径列表,它将在这些位置查找 PDB 文件。此外,如果_NT_SOURCE_PATH设置为以分号分隔的路径列表,它将在每个路径的子目录中搜索源文件。因此,设置这些环境变量将允许 PerfView 的源代码功能在“外部”计算机上工作。您还可以使用堆栈查看器菜单栏上“文件”菜单上的菜单项在 GUI 内设置_NT_SYMBOL_PATH和_NT_SOURCE_PATH。
另请参阅基于时间的调查教程。虽然目前没有关于进行 GC 堆分析的教程,但如果您还没有学习过基于时间的调查教程,您应该这样做。在内存调查中使用了许多相同的概念。您还应该看看
教程未完成
如简介中所述,ETW 是内置于 Windows 操作系统中的轻量级日志记录机制,可以收集有关计算机中发生的情况的各种信息。PerfView 支持通过两种方式收集 ETW 配置文件数据。
您还可以使用命令行选项自动收集配置文件数据。有关详细信息,请参阅从命令行收集数据。
如果您打算进行挂钟时间调查
默认情况下,PerfView 选择一组事件,这些事件不会生成太多数据,但对各种调查很有用。但是,挂钟调查需要的事件量太大,默认情况下无法收集。因此,如果您想进行挂钟调查,则需要在收集对话框中设置“线程时间”复选框。
如果要将 ETL 文件复制到另一台计算机进行分析
默认情况下,为了节省时间,PerfView 不会准备 ETL 文件,以便可以在其他计算机上对其进行分析(请参阅合并)。此外,还有符号信息(NGEN图像的PDBS),如果数据要在任何机器上正常工作,也需要包括这些信息)。如果您打算这样做,则需要使用“ZIP”命令合并并包含 NGEN pdbs。您可以这样做
压缩数据后,文件不仅包含解析符号信息所需的所有信息,而且还经过压缩以加快文件复制速度。如果您打算在另一台机器上使用数据,请指定ZIP选项。
收集数据的结果是一个 ETL 文件(可能还有一个 .kernel。ETL 文件,如合并中所述)。当您在主查看器中双击该文件时,它会打开所收集数据的“子视图”。其中一项将是“CPU 堆栈”视图。双击该按钮将打开一个堆栈查看器来查看收集的样本。ETL 文件中的数据包含系统中所有进程的 CPU 信息,但大多数分析都集中在单个进程上。因此,在显示堆栈查看器之前,首先会显示一个对话框,用于选择感兴趣的进程。
默认情况下,此对话框包含收集跟踪时处于活动状态的所有进程的列表,并按每个进程消耗的 CPU 时间量排序。 如果您正在进行 CPU 调查,则感兴趣的进程很有可能位于此列表的顶部附近。 只需双击所需的进程,就会调出过滤到您选择的进程的堆栈查看器。
通过单击列标题,可以按任何列对流程视图进行排序。 因此,如果您希望查找最近启动的进程,可以按开始时间排序以快速找到它。 如果视图按名称排序,则如果键入进程名称的第一个字符,它将导航到具有该名称的第一个进程。
进程筛选器文本框 进程列表正上方的框。如果在此框中键入文本,则仅显示与此字符串匹配的进程(PID、进程名称或命令行,不区分大小写)。* 字符是通配符。这是查找特定进程的快速方法。
如果您希望查看多个过程的样品进行分析,请单击“所有过程”按钮。
请注意,进程选择对话框的唯一效果是添加与您选择的进程匹配的“Inc Pats”过滤器。因此,该对话框实际上只是一个“友好界面”,用于堆栈查看器更强大的过滤选项。特别是,堆栈查看器仍然可以访问所有示例(甚至是所选进程之外的示例),只是由于对话框设置的包含模式,它将其过滤掉。这意味着您可以在分析的稍后时间点删除或修改此过滤器。
默认情况下,PerfView 堆栈查看器中显示的数据是在系统上的每个处理器上每毫秒执行一次的堆栈跟踪。每毫秒,任何正在运行的进程都会停止,操作系统会“遍历”与正在运行的代码关联的堆栈。进行堆栈跟踪时保留的是堆栈上每个方法的返回地址。堆叠行走可能并不完美。操作系统可能无法找到下一帧(导致堆栈损坏),或者优化编译器删除了方法调用(请参阅缺失的帧),这可能会使分析更加困难。然而,在大多数情况下,该方案运行良好,并且开销低(通常为 10% 的减速),因此可以在“生产”系统上进行监控。
在负载较轻的系统上,许多 CPU 通常处于“空闲”进程中,当操作系统没有其他操作可做时,该进程会运行该进程。 PerfView 会丢弃这些示例,因为它们几乎从不有趣。 然而,所有其他样品都会被保留,无论它们来自什么过程。 大多数分析都集中在单个进程上,并进一步筛选在感兴趣的进程中未发生的所有样本,但 PerfView 还允许你将所有进程中的样本视为一棵大树。 这在端到端涉及多个进程的情况下非常有用,或者当您需要多次运行应用程序以收集足够的样本时。
由于每个处理器每毫秒采集一次样本,因此每个样本表示 1 毫秒的 CPU 时间。 然而,取样的确切位置实际上是“随机的”,因此将整毫秒“充电”到取样时碰巧运行的例程中确实是“不公平的”。 虽然这是真的,但随着采集的样本越来越多,这种“不公平性”会随着样本数量的平方根而减少,这也是事实。 如果一种方法只有 1 或 2 个样本,那么它可能只是随机发生在该特定方法中,但具有 10 个样本的方法可能真正使用了 7 到 13 个样本(30% 误差)。 具有 100 个样本的例程可能在 90 和 110 之间(误差为 10%)。 对于“典型”分析,这意味着您至少需要 1000 个样本,最好是 5000 个样本(10K 后回报递减)。 通过收集几千个样本,您可以确保即使是中等程度的“温”方法也至少有 10 个样本,而“热”方法至少有 100 个样本,从而使误差保持在可接受的范围内。 由于 PerfView 不允许更改采样频率,这意味着需要运行方案至少几秒钟(对于 CPU 密集型任务),以及 10-20 秒(对于较少 CPU 密集型活动)。
如果要测量的程序不能轻易更改为在所需的时间内循环,则可以创建一个批处理文件,重复启动程序并使用它来收集数据。 在这种情况下,您需要查看所有进程的 CPU 示例,然后使用 GroupPat 擦除进程 ID(例如进程 {%}=>$1),从而将所有同名进程组合在一起。
即使有 1000 个样本,仍然存在至少在 3% 范围内的“噪声”(sqrt(1000) ~= 30 = 3%)。 随着所研究的方法/组的样本较少,此误差会变大。 这使得使用基于样本的分析来比较两条迹线来追踪小的回归(比如 3%)成为问题。 噪声可能至少与您试图追踪的“信号”(diff)一样大。 增加样本数量会有所帮助,但是在比较两条迹线之间的微小差异时,应始终牢记采样误差。
由于为每个样本收集堆栈跟踪,因此每个节点都具有一个独占指标(在该特定方法中收集的样本数)和一个非独占指标(在该方法或该方法调用的任何方法中收集的样本数)。通常,您对包含时间感兴趣,但重要的是要意识到折叠(参见 FoldPats 和 Fold %)和分组会人为地增加独占时间(它是该方法(组)中的时间以及折叠到该组中的任何内容)。当您希望查看折叠到节点中的内容的内部结构时,您可以钻取到组以打开一个视图,在该视图中可以撤消分组或折叠。
如果尚未执行此操作,请考虑逐步完成 尽早和经常测量性能 中的教程和最佳实践。
PerfView 中的默认堆栈查看器会分析进程的 CPU 使用率。 在开始对特定进程进行 CPU 分析时,应始终立即执行三件事。
如果上述任一条件失败,则分析的其余部分很可能不准确。 如果你没有足够的样本,你需要回去收集,以便你得到更多,修改程序以运行更长时间,或者多次运行程序以积累更多样本。 如果您的程序运行时间足够长(通常为 5-20 秒),并且您仍然没有至少 1000 个样本,则很可能是因为 CPU 不是瓶颈。 在启动方案中,CPU 不是问题,而是从磁盘获取数据所花费的时间是很常见的。 程序也可能正在等待网络 I/O(服务器响应)或来自本地系统上其他进程的响应。 在所有这些情况下,浪费的时间不受使用多少 CPU 时间的限制,因此 CPU 分析是不合适的。
您可以通过查看“最顶层”方法的“时间”列来快速确定您的进程是否受 CPU 限制。如果 When 列在活动期间有很多 9 或 As,则该进程很可能在这段时间内受 CPU 限制。这是您可以希望优化的时间,如果它不是应用程序总时间的很大一部分,那么优化它的整体效果将很小(参见阿姆达尔定律)。切换到 CallTree 视图并查看程序中一些最顶级方法的“When”列是确认应用程序实际上受 CPU 限制的好方法。
最后,你可能有足够的样本,但你缺乏符号信息来理解它们。这将以 ?在他们身上。默认情况下,.NET 代码应该“正常工作”。对于非托管代码,需要告诉 PerfView 你有兴趣获取哪些 DLL 的符号。有关详细信息,请参阅符号分辨率。您还应该快速检查您是否有很多损坏的堆栈,因为这也会干扰分析。
一旦确定 CPU 对于优化实际上很重要,您就可以选择如何进行分析。 性能调查可以是“自上而下”的(从主程序开始,以及如何将花费的时间划分为它调用的方法),也可以是“自下而上”(从实际采样的“叶”方法开始,并查找使用大量时间的方法)。 这两种技术都很有用,但是“自下而上”通常是更好的开始方式,因为底部的方法往往更简单,因此更容易理解,并且对它们应该使用多少 CPU 有直觉。
PerfView 从“ByName”视图开始,该视图是自下而上分析的适当起点。在自下而上的分析中,将方法分组到语义相关的分组中尤为重要。默认情况下,PerfView 会选择一个好的集合起始组(称为“只是我的代码”)。在此分组中,任何模块中位于 EXE 所在目录以外的目录中的任何方法都被视为“其他”,并且使用条目组功能,通过用于调用此外部代码的方法对它们进行分组。有关“Just My Code”分组含义的更多信息,请参阅教程,以及有关分组的更多信息,请参阅GroupPats参考。
对于简单的应用程序,默认分组效果很好。GroupPats 框的下拉列表中还有其他预定义的分组,您可以根据需要自由创建或扩展这些分组。当您在“ByName”视图中看到的是语义相关的方法名称时,您就知道您有一组“良好”的分组(您识别这些名称,并且知道它们的语义用途是什么),它们的数量不多(少于 20 个左右,具有有趣的独占时间), 但足以将程序分解成“有趣”的部分,您可以依次关注(通过钻取)。
一种非常简单的方法是增加 折叠百分比 ,这会折叠掉小节点。有一个快捷键可以增加(F7 键)或减少(Shift F7)1.6 倍。因此,通过反复按 F7,您可以将小节点“聚集”成大节点,直到只有少数节点存活并显示出来。虽然这既快速又简单,但它并没有注意到生成的组在语义上的相关性。因此,它可能会以糟糕的方式对事物进行分组(折叠掉语义相关的小节点,并将它们分组到您不太想看到的“辅助例程”中)。尽管如此,它是如此快速和简单,至少尝试看看会发生什么总是值得的。此外,折叠掉真正小的节点几乎总是有价值的。即使一个节点在语义上是相关的,如果它使用了总 CPU 时间的 1%,<,你可能并不关心它。
通常,当您在 1-10% 范围内使用 Fold % (以去除最小的节点),然后有选择地折叠任何语义上不有趣的节点时,会出现最佳结果。 这可以很容易地完成,查看“ByName”视图,按住“Shift”键,然后选择图表上具有一些独占时间的每个节点(它们将朝向顶部),而您却无法识别。 完成扫描后,只需右键单击并选择“折叠项目”,这些节点将被折叠到从视图中消失的调用方中。 重复此操作,直到显示中没有使用语义上不相关的独占时间的节点。 你所剩下的就是你要找的。
在调查的第一阶段,你花时间组建语义相关的组,这样你就可以理解如何为数百种单独的方法所花费的时间分配“意义”的“大局”。 通常,下一阶段是“钻取”这些似乎花费了太多时间的组之一。 在这个阶段,你有选择地取消对语义组的分组,以了解下一个抽象“较低层次”上发生的事情。
您可以使用两个命令完成此操作
通常,如果“取消分组”或“取消分组模块”命令效果不佳,请使用“清除所有折叠”如果效果不佳,请清除“GroupPats”文本框,该文本框将显示最“未分组”的视图。 如果此视图过于复杂,则可以使用显式折叠(或创建临时组)来构建新的语义分组(就像在分析的第一阶段一样)。
总之,CPU 性能分析通常包括三个阶段
很明显,优化时间的好处是:您的程序运行得更快,这意味着您的用户不会等待那么久。对于记忆来说,它并不那么清楚。如果您的程序使用的内存比它多 10%,谁在乎呢?有一篇有用的 MSDN 文章,名为 Memory Usage Auditing for .NET Applications,此处将对此进行总结。从根本上说,你真的只关心内存影响速度时,当你的应用程序变大时就会发生这种情况(TaskManager > 50 Meg 指示使用的内存)。但是,即使您的应用程序很小,也很容易对应用程序的总内存使用情况和 .NET 的 GC 堆,对于任何性能很重要的应用程序,您确实应该这样做。从字面上看,在几秒钟内,您可以获得 GC 堆的转储,并查看内存是否“合理”。如果您的应用确实使用了 50Meg 或 100 Meg 的内存,那么它可能会对性能产生重要影响,您需要花费更多时间来优化其内存使用。有关更多详细信息,请参阅文章。
即使您已经确定您关心内存,仍然不清楚您是否关心 GC 堆。如果 GC 堆仅占内存使用量的 10%,则应将精力集中在其他地方。您可以通过打开任务管理器,选择“进程”选项卡并找到进程的“内存(专用工作集)”值来快速确定这一点。(有关专用工作集的说明,请参阅 .NET 应用程序的内存使用情况审核)。接下来,使用 PerfView 拍摄同一进程的堆快照 (Memory -> Take Heap Snapshot)。视图顶部是“总指标”,在本例中为内存字节。如果 GC 堆是进程使用的总内存的很大一部分,则应将内存优化集中在 GC 堆上。
如果发现进程使用大量内存,但它不是 GC 堆,则应下载免费的 SysInternals vmmap 工具。此工具为您提供进程使用的所有内存的细分(它比 .NET 应用程序的内存使用审核中提到的 vadump 工具更好)。如果此实用程序显示托管堆很大,则应对此进行调查。如果它显示“堆”(即操作系统堆)或“私有数据”(即 virtualAllocs),则应调查非托管内存。
如果您尚未阅读何时关注内存和何时关注 GC 堆,请阅读以确保 GC 内存与您的性能问题相关。
Memory->Take Heap Snapshot 菜单项允许您拍摄任何正在运行的 .NET 应用程序的 GC 堆的快照。选择此菜单项时,它会打开一个对话框,显示系统上要从中进行选择的所有进程。
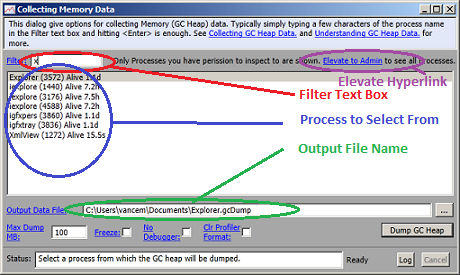
通过在筛选器文本框中键入进程名称的几个字母,可以快速减少显示的进程数。在上图中,只需键入“x”即可将进程数减少到 7,而键入“xm”就足以将其减少到单个进程 (xmlView)。双击该条目将选择该条目并启动堆转储。或者,您只需单击一下即可选择该进程,然后继续更新对话框的其他字段。
如果 PerfView 未以管理员身份运行,则可能不会显示感兴趣的进程(如果它不归你所有)。通过单击“提升到管理员”超链接,以管理员身份重新启动 PerfView,以查看所有进程。
转储过程是对话框的唯一必填字段,但如果需要,您可以设置其他字段。(有关详细信息,请参阅内存收集对话框参考)。要开始转储,请单击“转储堆”按钮或直接键入回车键。
一旦你有了一些GC堆数据,就必须了解你到底收集了什么,以及它的局限性是什么。从逻辑上讲,捕获的是堆中对象的快照,这些对象是通过遍历一组根的引用(就像 GC 本身一样)找到的。这意味着您只能发现在拍摄快照时处于活动状态的对象。然而,在正常情况下,有两个因素使这种表征不准确。
对于某些应用程序,GC 堆可能会变得非常大(> 1GB,可能达到 50GB 或更多),当 GC 堆 1,000,000 个对象时,它会大大减慢查看器的速度,并使堆转储文件的大小变得非常大。
为了避免此问题,默认情况下,PerfView 仅收集小于 50K 对象的堆的完整 GC 堆转储。在此之上,PerfView 仅获取 GC 堆的样本。PerfView 在挑选“好”样本时遇到了一些麻烦。特别
结果是,所有样本始终包含至少一个根路径(但可能不是所有路径)。 所有大型对象都存在,并且每种类型都至少具有代表性的样本数量(由于原因(5)和(6),可能更多)。
GC 堆采样仅生成 GC 堆中对象的转储部分,但我们希望该样本代表整个 GC 堆。PerfView 通过缩放计数来实现此目的。遗憾的是,由于需要包含任何大型对象和任何对象的根路径,因此单个数字将无法正确缩放采样堆,使其表示原始堆。PerfView 通过记住原始图形中每种类型的总大小以及缩放图形中的总计数来解决此问题。使用此信息,对于每种类型,它会缩放该类型的 COUNT,以便该类型的 SIZE 与原始 GC 堆匹配。因此,在查看器中看到的内容应该非常接近在原始堆中看到的内容(只是 PerfView 更小且更易于消化)。这样一来,大型对象(总是被采用)的计数将不会被缩放,但最常见的类型(例如字符串)将被大量缩放。在打开 .gcdump 文件时,可以通过查看日志来查看 PerfView 用于缩放的原始统计信息和比率。
当 PerfView 显示已采样(因此需要缩放)的 .gcdump 文件时,它将在显示顶部的摘要文本框中显示已缩放类型的 COUNTS 的平均量以及必须缩放 SIZES 的平均量。 这是您正在进行采样/缩放的指示,并注意可能存在一些采样失真。
重要的是要认识到,虽然缩放试图抵消采样的影响(因此显示“看起来”像真实的、未采样的图形),但它并不完美。PER-TYPE 统计信息 SIZE 应始终准确(因为这是用于执行缩放的指标,但 COUNT 可能不是。特别是对于实例大小可能不同的类型(字符串和数组),计数可能处于关闭状态(但是您可以在日志文件中看到真实数字)。此外,堆的 SUBSETS 的计数和大小可以关闭。
例如,如果向下钻取到堆的某个特定部分(例如所有 Dictionary),可能会发现键的计数(字符串类型)和值的计数(MyType 类型)不同。这显然是出乎意料的,因为每个条目都应该有一个条目。此异常是采样的结果。出现此类异常的可能性与您正在推理的堆子集的大小成反比。因此,当你对整个堆进行推理时,应该没有异常,但是如果你对某个子树深处的少量对象进行推理,则可能性非常高。
一般来说,这些异常往往不会对分析产生太大影响。这是因为您通常关心堆的大部分,而这正是采样最准确的地方。因此,通常对这些异常的正确反应是简单地忽略它们。但是,如果它们干扰了您的分析,则可以通过减少采样来减少或消除它们。采样由“Max Dump K Objs”字段控制。默认情况下,将收集 250K 个对象。如果将此数字设置为较大,则采样将减少。如果您将其设置为某个非常大的数字(例如 10 亿),则根本不会对图形进行采样。请注意,PerfView 示例是有原因的。当作的对象数超过 100 万个时,PerfView 的查看器将明显滞后。超过1000万,这将是一次非常令人沮丧的经历。PerfView 在操作如此大的图形时也很有可能会耗尽内存。它还会使 GCDump 文件按比例变大,并且复制起来很笨拙。因此,应仔细考虑更改默认值。使用采样转储通常是更好的选择。
如前所述,GCHeap 集合(适用于 .NET)收集 DEAD 对象和活动对象。 PerfView 之所以这样做,是因为它允许你查看 GC 的“开销”(已消耗的空间量,但未用于活动对象)。 它还更可靠(如果无法遍历根或对象,则不会丢失大量数据)。 当图形显示时,可以确定死对象,因为它们将通过“[无法从根访问]”节点。 通常,您对死对象不感兴趣,因此可以通过排除此节点 (Alt-E) 来排除死对象。
PerfView 能够冻结进程或允许其在收集 GC 堆时运行。如果进程被冻结,则生成的堆在该时间点是准确的,但是,由于即使对 GC 堆进行采样也可能需要 10 秒,这意味着该进程不会在该时间段内运行。对于“始终启动”的服务器,这是一个问题,因为 10 秒非常明显。另一方面,如果允许进程在收集堆时运行,则意味着堆引用会随时间而变化。事实上,GC 可能会发生,过去指向一个对象的内存现在可能已经死了,相反,将创建新对象,这些对象不会被之前在堆转储中捕获的根根。因此,堆数据将不准确。
因此,我们有一个权衡
PerfView 允许两者,但默认情况下它不会冻结进程。合理的是,对于大多数应用程序,您在进程等待用户输入时拍摄快照(因此进程无论如何都像是冻结一样)。例外情况是服务器应用程序。然而,这正是停止进程 10 秒可能很糟糕的情况。因此,在大多数情况下,允许进程运行的默认值更好。
此外,如果堆很大,则不会转储堆中的所有对象。只要正在运行的进程遗漏的对象在统计上与未移动的对象相似(可能在服务器进程中),那么堆统计信息对于大多数性能调查来说可能足够准确。
但是,如果出于某种原因希望消除正在运行的进程的不准确性,只需使用 Freeze 复选框或 /Freeze 命令行限定符来指示你对 PerfView 的希望。
如了解 GC 堆数据中所述,在 .GCDump 文件可能只是 GC 堆的近似值。尽管如此,.GCDump 确实捕获了堆是任意引用图的事实(一个节点可以有任意数量的传入和传出引用,并且引用可以形成循环)。从分析的角度来看,这种任意的图表很不方便,因为没有明显的方法可以以有意义的方式“汇总”成本。因此,数据被进一步调整以将图形变成一棵树。
基本算法是对堆进行加权广度优先遍历,最多访问每个节点一次,并且只保留在访问期间遍历的链接。因此,任意图形被转换为树(没有循环,每个节点(根除外)只有一个父节点)。默认权重旨在选择“最佳”节点作为“父节点”。直觉是,如果您可以选择两个节点作为特定节点的父节点,则需要选择语义上最相关的节点。
gc 堆内存数据的查看器有一个额外的“优先级”文本框,其中包含通过为每个对象分配浮点数值优先级来控制图形到树转换的模式。这是在两步过程中完成的,首先为类型名称分配优先级,然后通过类型为对象分配优先级。
“优先级”文本框是表单表达式的分号列表
其中 PAT 是简化模式匹配中定义的正则表达式模式,NUM 是浮点数。为类型分配优先级的算法很简单:在模式列表中找到与类型名称匹配的第一个模式。如果模式匹配,则分配相应的优先级。如果没有匹配的模式,则分配优先级 0。这样,每种类型都会被赋予优先级。
为对象分配优先级的算法同样简单。它从其类型的优先级开始,但它也在正在形成的生成树中增加了其“父级”的 1/10 优先级。因此,节点将其部分优先级分配给其子节点,因此这往往会鼓励广度优先行为(所有其他优先级相同,即距离具有给定优先级的节点 2 跳,将比距离 3 跳的节点具有更高的优先级)。
为所有“即将遍历”的节点分配优先级后,下一个节点的选择很简单。PerfView 选择优先级最高的节点进行接下来遍历。因此,具有高优先级的节点很可能是 PerfView 形成的生成树的一部分。这很重要,因为分析的所有其他部分都依赖于此生成树。
您可以在“优先级”文本框中查看默认优先级。此默认值背后的基本原理是:
因此,该算法倾向于首先遍历用户定义的类型,并找到路径中具有最多用户定义类型的最短路径。只有当这些链接用完时,它才会遵循框架类型(如集合类型、GUI 基础设施等),并且只有当这些类型用尽时,才会遍历匿名运行时句柄。当有选择时,这往往会将堆中对象的成本(大小)分配给语义更相关的对象。
默认值出乎意料地好,通常您不必增加它们。但是,如果确实为类型分配优先级,则通常希望选择 1 到 10 之间的数字。如果所有类型都遵循此约定,则通常所有子节点都将小于给定显式类型的任何类型(因为它被除以 10)。但是,如果要为节点指定优先级,以便其子节点具有较高的优先级,则可以为其指定一个介于 10 和 100 之间的数字。让这个数字更大,甚至会迫使孙子孙女“赢得”最优先的比较。通过这种方式,您可以强制图形的整个区域具有高优先级。同样,如果存在您不想看到的类型,则应为它们提供一个介于 -1 和 -10 之间的数字。
GUI 能够快速设置特定类型的优先级。如果您在 GUI 中选择文本,右键单击优先级 -> 提高项目优先级 (Alt-P),则该类型的优先级将增加 1。还有类似的“较低项目优先级 (Shift-Alt-P)”。同样,有一个提高模块优先级 (Alt-Q) 和降低模块优先级 (Shift-Alt-Q),它们与与所选单元格具有相同模块的任何类型相匹配。
由于图形已转换为树,因此现在可以明确地将“子项”的成本分配给父项。在这种情况下,成本是对象的大小,因此在根目录上,成本将加起来等于 GC 堆(实际采样)的总(可访问)大小。
将堆图转换为树后,可以在用于 ETW 调用堆栈数据的同一堆栈查看器中查看数据。但是,在此视图中,数据不是分配的堆栈,而是 GC 堆的连接图。您没有调用方和被调用方,而是推荐人和推荐人。没有时间的概念(“何时”、“第一”和“最后一列”),但包含和排他性时间的概念仍然有意义,分组和折叠操作同样有用。
需要注意的是,这种对树的转换是不准确的,因为它将子节点的所有成本归因于一个父节点(遍历中的父节点),而没有成本归因于恰好也指向该节点的任何其他节点。查看数据时请记住这一点。
如将堆图转换为堆树中所述,在显示内存数据之前,会将其从图形(其中圆弧可以形成循环并具有多个父项)转换为树(其中从节点到根始终只有一条路径)。属于此树的引用称为主参照,在查看器中以黑色显示。但是,查看已修剪的其他引用也很有用。这些其他引用称为辅助节点。当存在辅助节点时,主节点以粗体显示,辅助节点为正常字体粗细。有时,辅助节点会使显示混乱,因此会出现“仅 Pri1”复选框,选中该复选框时会抑制辅助节点的显示。
主节点比辅助节点有用得多,因为存在明显的“所有权”或“包容性”成本概念。谈论主节点的节点及其所有子节点的成本是有意义的。辅助节点不具有此特征。打开辅助节点很容易“迷路”,因为您可能正在遵循一个循环而没有意识到这一点。为了帮助避免这种情况,每个辅助节点都标有其“最小深度”。此数字是从集合中的任何节点到根节点的最短 PRIMARY 路径。因此,如果您尝试使用辅助节点找到根路径,那么跟踪深度较小的节点将带您到达那里。
但是,通常最好不要花时间打开辅助节点。显示这些节点的真正目的是允许您确定“优先级”文本框中的优先级是否合适。如果您发现自己对辅助节点感兴趣,那么最好的响应很可能是简单地添加一个优先级,使这些辅助节点成为主节点。通过这样做,您可以获得合理的包容性指标,这是理解内存数据的关键。
对我们来说,设置优先级的一个好方法是右键单击 -> 优先级 -> 增加优先级 (Alt-P) 并右键单击 -> 优先级 -> 降低优先级 (Alt-Q) 命令。通过选择一个有趣或明确不有趣的节点并执行这些命令,您可以提高或降低其优先级,从而使其位于主树中(或不在主树中)。
本节假设您已经确定 GC 堆是相关的,您已经收集了 GC 快照,并且您了解堆图是如何转换为树形的,以及堆数据是如何缩放的。除了此处完成的“正常”堆分析之外,使用 GCStats 报告以及 GC Heap Alloc Ignore Free (Coarse Sampling) 视图查看 GC 的批量行为也很有用。
与 CPU 时间调查一样,GC 堆调查可以自下而上或自上而下进行。与 CPU 调查一样,自下而上的调查是一个很好的起点。对于内存来说,这比对于 CPU 来说更是如此。原因是与 CPU 不同,视图中显示的树不是“事实”,因为树视图并不表示某些节点被多个节点引用的事实(即它们具有多个父节点)。正因为如此,自上而下的表示有点“武断”,因为你可以得到不同的树,这取决于图形的广度第一次遍历是如何完成的。自下而上的分析相对不受这种不准确性的影响,因此是更好的选择。
与 CPU 调查一样,自下而上的堆调查首先通过“折叠”任何语义不相关的节点来形成语义相关的组。这种情况一直持续到组的规模大到足以引起人们的兴趣为止。然后,可以使用“钻取”功能来启动子分析。如果您不熟悉这些技术,请参阅 CPU 教程。
Goto 调用方视图 (F10) 对于堆调查特别有用,因为它可以快速汇总 GC 根的路径,这些路径指示对象仍处于活动状态的原因。当您发现已经过时的对象时,必须断开其中一个链接,GC 才能收集它。需要注意的是,由于视图显示的是对象的 TREE 而不是 GRAPH,因此可能存在指向对象的其他路径未显示。因此,要使对象死亡,必须切断调用者视图中的一条路径,但这可能还不够。
通常,GC 堆由
不幸的是,虽然这些类型在堆的大小中占主导地位,但它们对分析并没有真正的帮助。你真正想知道的不是你使用了很多字符串,而是你控制的对象使用了很多字符串。好消息是,这是“标准问题”,即自下而上的分析,PerfView确实可以很好地解决。默认情况下,PerfView 会添加折叠模式,这些模式会导致所有字符串和数组的成本都记入引用它们的对象(就像字段被“内联”到引用它的结构中一样)。因此,其他对象(更有可能与您在语义上相关)将收取此费用。此外,默认情况下,“Fold%”文本框设置为 1,这表示应删除使用少于 1% 的 GC 堆的任何类型,并向引用它的人收取其成本。
GC 堆的自下而上分析与 CPU 调查大致相同。您可以使用 Stack Viewer 的分组和折叠功能来消除干扰并形成更大的语义相关组。当这些组足够大时,您可以使用“钻取”功能来隔离此类组,并在更详细级别上理解它。通过对应用程序内存使用情况的详细了解,您可以了解最有价值的优化位置。
确定要关注的类型后,了解类型的分配位置通常很有用。有关更多信息,请参阅 GC Alloc Stacks 视图。
一种常见的内存问题是“内存泄漏”。这是一组已达到其目的且不再有用的对象,但仍连接到活动对象,因此无法由 GC 堆收集。如果您的 GC 堆随着时间的推移而增长,则很有可能存在内存泄漏。各种类型的缓存是“内存泄漏”的常见来源。
内存泄漏实际上只是正常内存调查的一个极端情况。在任何内存调查中,您都会将语义相关的节点组合在一起,并评估您看到的成本是否因它们为程序带来的价值而合理。在内存泄漏的情况下,该值为零,因此通常只需找到成本即可。此外,还有一种非常简单的方法来查找泄漏
请注意,由于程序通常具有“一次性”缓存,因此通常需要修改上述过程。在获取基线之前,您需要执行一次或两次操作集。这样,在捕获基线时,任何“准时”缓存都将被填满,因此不会显示在差异中。
当您发现可能的泄漏时,请使用节点上的“转到调用方视图 (F10)”来查找从根到该特定节点的路径。这将显示使此对象保持活动状态的对象。若要解决此问题,必须断开其中一个链接(通常通过清空对象字段)。
虽然自下而上分析通常是最好的开始方式,但通过查看 CallTree 视图来“自上而下”查看树也很有用。GC 堆的顶部是图形的根。这些根中的大多数要么是主动运行方法的局部变量,要么是各种类的静态变量。PerfView 不厌其烦地尝试获取有关根的尽可能多的信息,并按程序集和类对它们进行分组。快速查看哪些类占用了大量堆空间通常是发现泄漏的快速方法。
但是,应谨慎使用此技术。如将堆图转换为堆树一节所述,虽然 PerfView 尝试为节点查找语义上最相关的“父节点”,但如果一个节点有多个父节点,则 PerfView 实际上只是猜测。因此,可能有多个类“负责”一个对象,而您只看到一个。因此,将责任归咎于被任意选择为高成本节点的唯一“所有者”的类可能是“不公平的”。尽管如此,调用树视图中的路径至少是部分原因,并且至少值得进一步调查。请记住视图的局限性。
PerfView 使用 .NET 调试器接口收集有关 GC 堆根的符号信息。有时(通常是因为程序在旧的 .NET 运行时上运行)PerfView 无法收集此信息。如果 PerfView 无法收集此信息,它仍然会转储堆,但 GC 根是匿名的,例如,一切都是“其他根”。请参阅 GC 堆转储时的日志,以确定无法收集此信息的确切原因。
典型的 GC 内存调查包括 GC 堆的转储。虽然这提供了有关创建快照时堆的非常详细的信息,但它没有提供有关一段时间内 GC 行为的信息。这就是 GCStats 报告的作用。若要获取 GCStats 报告,必须像 CPU 调查一样收集事件数据(默认情况下,GC 事件处于打开状态)。当您打开生成的 ETL 文件时,其中一个子项将是“GCStats”视图。打开它,系统上每个进程都会有一份报告,详细说明 GC 堆的位、GC 发生的时间以及每个 GC 回收的量。此信息对于大致了解 GC 堆如何随时间变化非常有用。
除了 GC 统计信息报告所需的信息外,正常的 ETW 事件数据收集还将包括有关对象分配位置的粗略信息。每次分配 100K 个 GC 对象时,都会进行堆栈跟踪。这些堆栈跟踪可以显示在 ETL 文件的“GC Heap Alloc Stacks”视图中。
这些堆栈显示了大量字节的分配位置,但是它不会告诉您这些对象中哪些快速死亡,哪些对象继续存在以增加整个 GC 堆的大小。正是这些后面的对象是最严重的性能问题。但是,通过查看堆转储,您可以看到实时对象,并且在确定某个特定对象具有许多存在时间较长的实例之后,查看它们的分配位置会很有用。这就是 GC Heap Alloc Stacks 视图将向您显示的内容。
请记住,粗略的采样非常粗略。实际上,只有碰巧“绊倒”100KB 采样计数器的对象才会被采样。但是,事实是,所有大小超过 100K 的对象都将被记录下来,并且任何分配了大量小对象也可能被记录下来。在实践中,这已经足够了。
.NET 堆将堆分为“大对象”(超过 85K)和小对象(低于 85K),并完全不同地处理它们。 特别是,大型对象仅在第 2 代 GC 上收集(很少见)。 如果这些大型对象存在很长时间,一切都很好,但是如果大型对象被分配了很多,那么要么你使用了大量内存,要么你创建了大量垃圾,这将迫使大量 Gen 2 集合(这很昂贵)。 因此,不应分配许多大型对象。 GC Heap Alloc 视图有一个特殊的“LargeObject”伪帧,如果对象很大,它会注入该伪帧,从而非常容易找到分配大型对象的所有堆栈。 这是 GC Heap Alloc Stacks 视图的常见用法。
调查 .NET GC 堆的内存使用率过高的首选是拍摄 GC 堆的堆快照。这是因为对象之所以保持活动状态,是因为它们已获得 root 权限,并且此信息会显示使内存保持活动状态的所有路径。但是,有时了解分配堆栈很有用。GC Heap Alloc Stacks 视图显示这些堆栈,但它不知道对象何时死亡。还可以打开额外的事件,使 PerfView 能够跟踪对象释放和分配,从而计算在 GC 堆上分配的 NET 内存量 (以及这些分配的调用堆栈) 。有两个详细级别可供选择。它们都位于集合对话框的高级部分中
在这两种情况下,它们还会记录对象何时被销毁(以便可以计算网络)。 在每次分配时触发事件的选项非常冗长。 如果您的程序分配了很多,它可能会减慢 3 或更多。 在这种情况下,文件也会很大(> 10-20 秒的跟踪为 1GB)。 因此,最好从第二个选项开始,即每 10KB 的分配触发一个事件。 这通常远低于开销的 1%,因此不会对运行时间或文件大小产生太大影响。 对于大多数目的来说,这已经足够了。
启用这些事件时,只有 .NET 进程在开始数据收集后启动。 因此,如果要分析长时间运行的服务,则必须重新启动应用程序才能收集此信息。
获得数据后,您可以在“GC Heap Net Mem”中查看数据,该数据显示所有分配的调用堆栈,其中指标为 GC Net GC 堆的字节数。GC Heap Alloc Stacks 和“GC Heap Net Mem”之间最显着的区别是,前者显示所有对象的分配堆栈,而后者仅显示那些尚未进行垃圾回收的对象的分配堆栈。
使用“.NET Alloc”复选框或“.NET SampAlloc”复选框收集的跟踪之间显示的内容基本上没有区别。 只是在 .NET SampAlloc 的情况下,信息可能不准确,因为特定的调用堆栈和类型被“收费”为 10K 的大小。 但是,从统计学上讲,如果收集了足够的样本,它应该为您提供相同的平均值。
.NET Net 分配分析的工作方式与非托管堆分析的工作方式相同。
PerfView 的目标之一是使界面始终保持响应。 这方面的表现是大多数窗口底部的状态栏。 此栏显示一行输出区域以及操作是否正在进行的指示、“取消”按钮和“日志”按钮。 每当长时间操作开始时,状态栏将从“就绪”更改为“正在工作”并闪烁。 取消按钮也会变为活动状态。 如果用户变得不耐烦,他可以随时取消当前操作。 还有一条单行状态消息,会随着进度的进行而更新。
执行复杂操作(如首次执行跟踪或打开跟踪)时,还会收集详细的诊断信息并将其存储在状态日志中。 当出现问题时,此日志可用于调试问题。 只需单击右下角的“日志”按钮即可查看此信息。
在主视图中,您有三个基本选择:
虽然我们建议您学习本教程,并查看收集事件数据和了解性能数据,但如果您的目标是尽快查看基于时间的配置文件数据,请按照以下步骤操作
虽然我们建议您学习本教程,并查看收集 GC 堆数据和了解 GC 堆数据,但如果您的目标是尽快查看内存配置文件数据,请按照以下步骤操作
实时进程收集
进程转储收集
除了常规提示之外,以下是特定于主视图的提示。
主视图是首次启动 PerfView 时迎接你的视图。 主视图有三个主要用途
下图突出显示了主视图的重要部分。
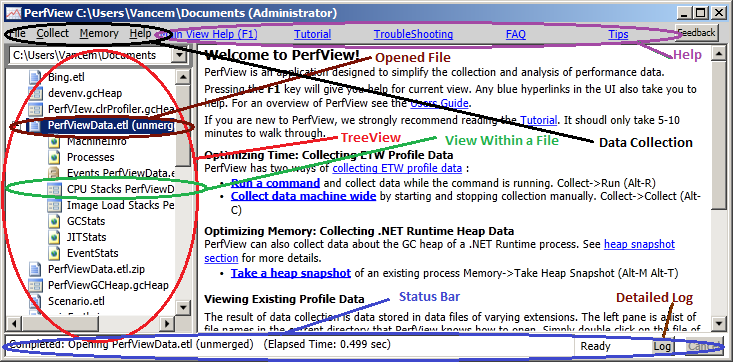
通常,首次使用 PerfView 时,会使用它来收集数据。 PerfView 目前可以收集以下类型的调查的数据
PerfView 了解的数据类型
待办事项未完成
除了常规提示之外,下面还有特定于对象查看器的提示。
对象查看器是一个视图,可用于查看有关 GC 堆上单个对象的特定信息。
待办事项未完成
虽然我们建议您学习本教程,但如果您的目标是了解堆栈查看器显示的内容,请按照以下步骤操作
您可以使用“文件 -> 设置为默认分组/折叠”菜单项来设置 GroupPats 和 Fold 文本框中使用的默认值。这三个值在该计算机的 PerfView 会话中保留。“File -> Clear User Config”会将这些持久化值重置为默认值,这是撤消错误的简单方法。
虽然我们建议您学习本教程,并查看了解 GC 堆性能数据和开始分析 GC 堆转储,但如果您的目标是尽快查看内存配置文件数据,请按照以下步骤操作
除了常规提示之外,这里还有特定于 Stack Viewer 的提示。
堆栈查看器是执行性能分析的主窗口。如果您尚未完成本教程或有关开始分析和理解性能数据的部分,那么这些内容将值得一读。这是堆栈查看器的布局
堆栈查看器有三个主要视图:ByName、Caller-Callee 和 CallTree。每个视图在堆栈查看器中都有自己的选项卡,可以使用这些选项卡进行选择。但是,更常见的情况是,使用右键单击或键盘快捷键从一个视图中的节点跳转到另一个视图中的同一节点。双击任何视图中的任何节点,实际上将带您进入Caller-Callee视图,并将焦点设置在该节点上。
无论选择哪种视图,所考虑的样本以及这些样本的分组对于每个视图都是相同的。此筛选和分组由视图顶部的文本框控制,分组和筛选部分对此进行了详细描述。
堆栈查看器的最顶部是汇总统计信息行。这为您提供了有关所有样本的统计信息,包括计数和总持续时间。它计算“TimeBucket”大小,该大小定义为跟踪总时间间隔的 1/32。这是“时间”列中每个字符所表示的时间量。
它还计算指标/间隔。这是对整个跟踪的 CPU 绑定程度的快速度量。值 1 表示平均占用单个处理器的所有 CPU 的程序。除非它很高,否则您的问题不是 CPU(它可能是一些阻塞操作,例如网络/磁盘读取)。
但是,此指标在收集数据时是平均值,因此可以包括感兴趣的进程甚至未运行的时间。因此,通常最好将节点的 When 列用于将进程作为一个整体呈现的节点,以确定进程的 CPU 绑定程度。
除了分组/筛选文本框之外,堆栈查看器还具有查找文本框,可用于搜索(使用 .NET 正则表达式)具有特定名称的节点。
堆栈查看器网格中显示的列与显示的视图无关。 只需将列标题拖动到所需的位置即可对列进行重新排序,并且可以通过单击列标题文本右侧的列标题中的(通常不可见的)按钮对大多数列进行排序。 显示的列包括:
PerfView 显示中的许多列都可用于对显示进行排序。您可以通过单击列顶部的列标题来执行此操作。再次单击可切换排序方向。请务必避免点击超链接文本(很容易不小心点击超链接)。单击顶部附近通常有效,但您可能需要使列标题变大(通过拖动其中一个列标题分隔符)。已经有人请求更改超链接,以便更轻松地访问列排序功能。
有一个已知的错误,即一旦按列排序,搜索功能就不会遵循新的排序顺序。这意味着在查找下一个实例时,搜索似乎会随机跳转。
堆栈查看器的默认视图是 ByName 视图。在此视图中,将显示每个节点(方法或组),并缩短为该节点的总 EXCLUSIVE 时间。这是用于自下而上分析的视图。有关使用此视图的示例,请参阅教程。双击条目将转到所选节点的调用方-被调用方视图。
有关详细信息,请参阅堆栈查看器。
调用树视图显示每个方法如何调用其他方法,以及与从根开始调用的每个方法关联的样本数。它是进行自上而下分析的合适视图。每个节点都有一个与之关联的复选框,选中后显示该节点的所有子节点。通过选中复选框,您可以向下钻取到特定方法,从而发现任何特定调用对进程使用的总 CPU 时间的贡献。
调用树视图也非常适合“放大”到感兴趣的区域。 通常,您只对程序特定部分的性能感兴趣(例如,鼠标单击与该单击相关的显示更新之间的时间) 通常,通过使用“主程序”节点上的“当”列查找 CPU 使用率较高的区域,可以很容易地发现这些时间区域。 或者,通过使用“SetTimeRange”命令查找已知与活动关联的函数的名称来限制调查范围。
与所有堆栈查看器视图一样,分组/过滤参数在形成调用树之前应用。
如果堆栈查看器窗口已启动以显示所有进程的样本,则每个进程只是“ROOT”节点之外的一个节点。 当您调查“为什么我的机器很慢”并且您真的不知道要查看哪个过程时,这很有用。 通过打开 ROOT 节点并查看 When 列,可以快速查看哪个进程正在使用 CPU 以及在哪个时间段内使用。
有关使用此视图的示例,请参阅教程。有关详细信息,请参阅堆栈查看器。有关不同的视觉表示,请参阅火焰图。
调用方-被调用方视图旨在让您专注于单个方法的资源消耗。通常,您可以通过双击节点名称从 ByName 或 Calltree 视图导航到此处。如果您有感兴趣的特定方法,请在 ByName 视图中搜索它(查找文本框),然后双击该条目。
ByName 视图具有“当前节点”的概念。 这是感兴趣的节点,是显示器中心的网格线。 然后,显示屏在下部网格中显示当前节点调用的所有节点(方法或组),并在上部窗格中显示调用当前节点的所有节点。 通过双击上部或下部窗格中的节点,可以将当前节点更改为新节点,并以这种方式在调用树中上下导航。
但是,与 CallTree 视图不同的是,Caller-Callee 视图中的节点表示当前节点的所有调用。 例如,在 CallTree 视图中,表示“SpinForASecond”的节点表示该函数的所有实例,这些实例具有相同的根路径。 因此,您将在 CallTree 视图中看到“SpinForASecond”的多个实例。 但是,如果我试图了解“SpinForASecond”对整个程序的影响,则很难在CallTree视图中这样做,因为它将查看所有这些节点。 Caller-Callee 视图聚合了“SpinForASecond”的所有不同路径,因此您可以快速了解整个程序中“SpinForASecond”的所有调用方和“SpinForASecond”的所有被调用方。
重要的是要意识到,当您双击不同的节点以使当前的样本集发生变化时。 当当前节点为“SpinForASecond”时,此视图仅显示其调用堆栈中具有 SpinForASecond“的示例。 但是,如果双击“DateTime.get_Now”(“SpinForASecond”的子项),则视图现在将包含“DateTime.get_Now”由不包含“SpinForASecond”的调用堆栈调用的示例,并且不包括调用“SpinForASecond”但不包括“DateTime.get_Now”的调用堆栈。 如果您不知道它正在发生,这可能会令人困惑。
有时,您希望查看从特定节点访问根目录的所有方法。 由于更改样本集的问题,您不能直接使用调用方-被调用方视图执行此操作。 您可以简单地在 CallTree 视图中搜索节点,但它不会按权重对路径进行排序,这使得查找“最重要”路径变得更加困难。 但是,您可以选择当前节点,右键单击并选择“包含项目”。 这将导致所有不包含当前节点的样本被过滤掉。 这不应更改当前调用方-被调用方视图,因为该视图已仅考虑包含当前节点的节点。 但是,现在,当您将其他节点设置为当前节点时,它们也将仅考虑包含原始节点以及新当前节点的节点。 通过单击调用方节点,您可以追溯到根目录的路径。
由于调用方-被调用方视图聚合了其调用堆栈中具有当前节点 ANYWHERE 的所有样本,因此递归函数存在一个基本问题。 如果单个方法在堆栈上多次出现,则幼稚的方法会多次计算相同的单个样本(调用堆栈上的每个实例一次),从而导致错误的结果。 您可以通过仅计算堆栈上第一个(或最后一个)实例的样本来解决重复计数问题,但这会扭曲调用方-被调用方视图(看起来递归函数从不调用自身,这也是不准确的)。 PerfView 选择的解决方案是“拆分”示例。 如果一个函数在堆栈上出现 N 次,则每个实例的样本数量为 1/N。 因此,样本不会重复计算,但它也以合理的方式显示所有调用方和被调用方。
有关详细信息,请参阅堆栈查看器。
调用方视图显示方法的所有可能调用方。 它是一个树视图(类似于调用树视图),但节点的“子节点”是节点的“调用者”(因此它是从调用树视图“向后”的)。 一种非常常见的方法是在“byname”视图中找到一个相当大的节点,查看其调用者(“通过双击 byname 视图中的条目”),然后查看是否有更好的语义分组“堆栈”应该折叠到该节点中。
如果双击“调用方”视图中的某个条目,则该条目将成为“调用方”视图、“被调用方”视图和“调用方-被调用方”视图的焦点节点。 因此,双击一个条目,切换到 Callees 视图,双击另一个条目并切换回来是相当常见的。
在调用方视图中,顶部节点始终是特定方法的所有用法的聚合,而不管调用方是谁。因此,顶行的统计信息应始终与“按名称”视图中的统计信息一致。此外,节点的任何子节点都表示父节点的调用方。这意味着
“调用方”视图中的任何子节点都表示父节点的调用方。它们将始终具有 0 的独占时间,因为根据定义,调用者不是堆栈的终端方法(因为它调用了其他方法)。
调用方视图和被调用方视图都是通过查找包含焦点帧的所有样本以及查看相应的相关节点(调用方或被调用方)相关帧而形成的。但是,当焦点帧是递归函数时,有一个,因为调用方和被调用方有多种选择,具体取决于选择的递归实例。
PerfView 通过始终选择堆栈中递归函数的“最深”实例来解决此问题。因此,如果 A 调用 B 调用 C 调用 B 调用 D,并且焦点节点是 B,则此示例将具有 C(不是 A)的调用方和 D(不是 C)的被调用方。
被调用方视图是一个树视图,用于显示给定节点的所有可能的被调用方。 它与树视图非常相似,但是树视图始终从根开始,而被调用方视图始终从“焦点”节点开始,并包括到达该被调用方的所有堆栈。 在调用树视图中,节点的不同实例将分散在调用树中,并且很难集中注意力。
如果双击“被调用方”视图中的某个条目,则该条目将成为被调用方视图、“被调用方”视图和“被调用方-被调用方”视图的焦点节点。 因此,双击一个条目,切换到“调用方”视图,双击另一个条目并切换回来是相当常见的。
与调用方的观点一样,当涉及递归函数时,存在重复计数的问题。有关详细信息,请参阅“调用方”和“被调用方”视图中的递归处理。
火焰图视图显示的数据与调用树视图相同,但使用不同的可视化效果。它为您提供了非常易于理解的概述。该图从底部开始。每个框表示堆栈中的一个方法。每个父母都是被召唤者,孩子是被召唤者。盒子越宽,它在 CPU 上的时间就越长。样本计数显示在工具提示和底部面板中。要更改火焰图的内容,您需要应用调用树视图的过滤器。要了解有关火焰图的更多信息,请访问 http://www.brendangregg.com/flamegraphs.html
PerfView 中的火焰图视图传统上反映消耗的内存量,但在绘制堆栈差异时,这可能会发生变化。垃圾回收后,在堆栈差异中检查类型消耗的内存量时,该类型消耗的内存量可能为负数。在这些情况下,相应的火焰图框以蓝色调绘制,表示内存增益。像往常一样,使用黄色/红色调绘制增加的内存使用量。
这使您可以记笔记。此视图包含的数据与“注释窗格”中的数据相同,您可以使用 F2 键进行切换。 这些注释在保存视图时保存,因此允许您保留在调查期间需要跟进的潜在顾客等信息。 笔记窗格特别有用,您需要将调查“移交”给另一个人。 通过将性能问题的“解释”放在便笺窗格中,并发送保存的视图,下一个人可以从您离开的地方“继续”。
通常情况下,分组和过滤参数定义变得相当复杂,但它们具有相对简单的语义含义。 能够保存这些参数并将其重用于其他调查也很有用。 为此,可以为过滤器参数集指定一个名称(只需在名称文本框中输入文本,以后可以使用此名称来标识此过滤器参数集)。
命名参数集是当前未由 PerfView 使用的。
PerfView 能够获取两个堆栈视图之间的差异。 这对于了解由最近更改引起的回归的原因非常有用。 要使用此功能,您应该
然后,PerfView 将打开一个堆栈视图,其中包含所选的“测试”视图和“基线”之间的差异。 它用来执行此操作的算法非常简单。 它只是否定基线的指标,然后将这些样本与测试样本(未修改)组合在一起。 结果是具有样本的跟踪,该样本具有“测试”和“基线”的样本之和,但是基线中所有样本的计数值和指标值为负。这意味着计数和指标值通常会“抵消”,只留下测试中的内容,而不是基线。
与正常调查一样,您应该使用“按名称”视图开始“差异”调查。 在典型的调查中,“测试”跟踪的指标(回归)严格多于基线,这反映在差异的总数中(差异的总指标应为测试的总指标减去基线的总指标)。 然后,“ByName”视图显示这种差异与使用“GroupPats”选择的组有关(就像正常跟踪一样)。
如果幸运的话,“按名称”视图中的每一行都是正数(或非常小的负数)。 这是“简单”的情况,当这种情况发生时,你就有了你感兴趣的信息(在测试中有额外成本但没有基线的精确组位于“按名称”视图的顶部。 从这一点开始,差异调查就像普通调查一样工作(您可以向下钻取、查看其他视图、更改分组、折叠等......
但是,视图中出现较大的负值的情况并不少见。 当这种情况发生时,差异不是那么有用,因为我们对测试跟踪中的 ADDITIONAL 时间感兴趣,但视图中的负数告诉我们,基线使用的时间比测试多的地方很大。 显然,总和必须加起来才能得到最终的回归,但只要视图中存在较大的负值,我们就不能信任视图中的大正值,因为它们可能会被负值抵消。
因此,对差异跟踪的分析始终有一个加法步骤:在形成差异视图之后,但在进行任何分析之前,必须使用分组/折叠/过滤运算符来确保负值已被充分“抵消”。视图只需要具有正度量数(或无关紧要的负数)。
事实上,PerfView 已经对此有所帮助。 通常,堆栈显示中的进程和线程节点包含该节点的进程和线程 ID。 虽然这是有用的信息,但它也意味着基线和测试跟踪中的节点可能永远不会匹配(因为它们具有不同的 ID)。 如果不加以纠正,这将导致“TreeView”变得非常无用(它将在“测试”过程中显示一个较大的正数,在“基线”下显示一个稍小的大负数,但不会取消。 PerfView 通过提供有效从节点中删除进程和线程 ID 的分组来解决此问题。 现在节点匹配,您将获得所需的取消。
但是,PerfView 只能做这么多。 它可以预测到需要重写进程和线程 ID,但它无法知道您重命名了某个函数,或者延迟初始化导致某些初始化的成本从一个位置移动到另一个位置。 简而言之,PerfView 无法知道您希望忽略的所有“预期”差异。 作为分析师,你的工作是使“预期”差异“完全匹配”,从而抵消。
PerfView 强大的折叠和分组运算符是用于创建此取消的工具。 要记住的口头禅是“分组是你的朋友”,保持你的小组尽可能大。 特别
这种策略背后的基本原理很简单。 你形成的群体越大,“无关紧要”的差异就越有可能简单地“抵消”。 模块往往是最有用的“大组”,因此按模块对所有样本进行分组可能会向您显示取消起作用的视图(视图中只有小负数)。 一旦确定了特定模块中负责回归的样本,就可以使用“钻取”功能来隔离这些样本,并更改分组以显示更多详细信息。 这往往是一个非常有用的策略。
在差异中实现取消的主要技术是选择大组,然后仅钻取感兴趣的样本。 但是,还有一些其他有用的事情需要记住。
修复重命名的函数
分组允许您将任何节点名称重命名为任何其他节点名称。 因此,您可以“修复”跟踪中的任何“预期”差异。 例如,如果 MyDll!MethodA 已重命名为 MyDll!MethodB,您可以添加分组模式
我的Dll!方法A->方法A;我的Dll!方法B->方法AAl!方法B->方法A
这将它们都“重命名”为简单的“MethodA”并解决差异。 折叠也可以用来解决这样的差异。 例如,如果这两种方法对事件不感兴趣(您不需要在调用堆栈上看到它们),那么您可以简单地使用折叠模式始终折叠它们
方法A;方法B
这使得它们都消失了(因此不会造成差异)。
超重分析是一种相当简单的技术,其中分析了两条迹线中所有符号的包含成本。通常使用时间指标,但任何包含成本都可以。
这个想法是这样的:使用基础和测试运行,很容易获得回归的整体大小。假设它是 10%。从那里你可以把一切都慢 10% 作为你的零假设。您要查找的是变化超过 10% 的符号,因此在某种意义上对更改负有更大的责任。在这种情况下,增持报告将简单地计算实际增长与预期增长 10% 的比率。当您发现超重超过 100% 的符号时,这些符号会引起极大的兴趣。
假设 main 调用 f 和 g,不做其他任何事情。每个需要 50 毫秒,总共 100 毫秒。现在假设 f 变慢,到 60 毫秒。现在的总数是 110,或恶化了 10%。这个算法将如何提供帮助?好吧,让我们看看增持。当然,主要是 100 到 110,或者说 10%,这是全部,所以预期增长是 10,实际是 10。超重100%。那里没什么可看的。现在让我们看一下 g,它是 50,保持在 50。但它“应该”去 55。超重 0/5 或 0%。最后,我们的大赢家,f,它从50上升到60,增加了10。在10%的增长下,它应该获得5。超重 10/5 或 200%。问题出在哪里非常清楚!但实际上它变得更好了。
假设 f 实际上有两个孩子 x 和 y。每个过去需要 25 毫秒,但现在 x 减慢到 35 毫秒。如果没有归因于 y 的收益,则 y 的超重将为 0%,就像 g 一样。但是,如果我们看一下x,我们会发现它从25上升到35,增加了10,它应该只增长2.5,所以它的超重是10/2.5或400%。在这一点上,模式应该很清楚:
当您靠近子树的根时,超重数字会不断上升,这是问题的根源。低于此值的所有内容都倾向于具有相同的超重。例如,如果问题是 f 再次调用 x,您会发现 x 及其所有子项都具有相同的超重数。
这将我们带到了该技术的第二部分。您想要选择一个具有较大超重但同时负责较大部分回归的交易品种。因此,我们计算其增长并除以总回归成本,得到责任百分比。这很重要,因为有时您得到的叶函数有 2 个样本,并且仅仅因为采样误差而增长到 3 个。这些可能看起来像是巨大的超重,所以你必须专注于具有合理责任百分比和大幅超重的方法。该报告会自动过滤掉责任小于 +/- 2% 的任何内容。
本摘要的大部分内容都可以在线获得,此处提供了更多示例。
事件查看器是一项相对高级的功能,可让您查看 ETL 文件中收集的“原始”事件。 尽快开始
除了常规提示之外,下面还有特定于事件查看器的提示。
某些数据文件(目前在 XPERF、csv 和 csvz 文件上)支持按时间排序的任意事件的视图。 事件查看器是用于显示此数据的窗口。 基本上,它是按时间顺序排列的事件视图,可以对其进行过滤和搜索。 一个典型的方案是,应用程序已使用事件(如 System.Diagnostics.Tracing.EventSource)进行检测,这些事件用于确定感兴趣的时间。
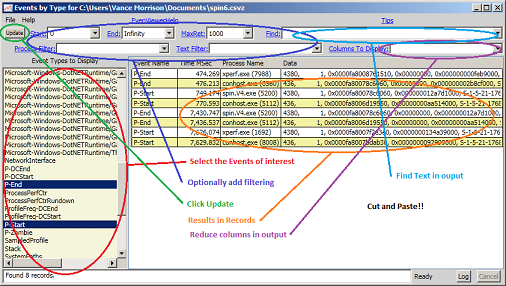
视图有两个主面板。 左侧的面板包含跟踪中的所有事件类型。 您只需按住控制键单击感兴趣的选项即可选择感兴趣的选项(同时选择多个。 右侧窗口包含实际事件记录。 对数据执行扫描以形成列表的成本相对较高,因此您必须明确要求更新正确的面板。 您可以通过多种方式执行此操作
除了按事件类型进行筛选外,您还可以通过在“流程过滤器”文本框中放置文本来按流程进行过滤。此文本是 .NET 正则表达式,仅选择具有与此文本匹配的进程的记录。匹配不区分大小写,只需匹配进程名称中的子字符串。您可以使用标准正则表达式 ^ 和 $ 运算符来强制匹配完整字符串。请注意,对于上下文切换事件,进程筛选器将匹配正在切换的进程 (OldProcessName) 以及切换到的新进程 (ProcessName)。
跟踪可能非常大,因此可以在右侧面板中返回大量结果。 为了加快速度,返回合理数量(默认为 10000 条)的记录。 这是“MaxRet”值。 如果它太小,可以将此文本框更新为更大的内容。
除了按进程筛选外,还可以按返回事件中的文本进行筛选。仅显示整个显示文本与模式匹配的记录。因此,如果更改显示的列,如果“文本过滤器”文本框中有文本,则可能会影响过滤。“文本筛选器”中的字符串被解释为 .NET 正则表达式,默认情况下,与进程筛选器一样,匹配只需匹配子字符串即可成功。如果模式以“!”字符开头,则仅显示与模式不匹配的条目。
特定于事件的字段在“数据”列中显示为一系列 NAME=VALUE 对。 此数据列可能很长,并且通常最感兴趣的元素位于末尾,因此视图不方便。 您可以通过在“要显示的列”文本框中放置字段名称(不区分大小写)来指示要显示哪些特定于事件的列来解决此问题。 这可以通过单击“列”按钮轻松填充。 这将显示所有列的弹出列表,您只需单击感兴趣的列(shift 和 ctrl 单击以选择多个条目),然后按“输入”继续。 这些列将按您选择项目的顺序显示,并且“*”可用作表示尚未选择的所有列的通配符。最多 4 个字段将显示在它们自己的列中。在前 4 列之后,指定列的其余部分将显示在“rest”列中。
可以使用“要显示的列”文本框通过指定表达式和布尔运算符来筛选事件:||和 && 基于方括号 ([]) 内的选定列。单个查询的格式为:LeftOperand 运算符 RightOperand,其中:
[(ThreadID == 1,240) && (ProcessName == devenv)] ThreadID ProcessorNumber [(GC/Start::Depth > 1) && (ProcessName==devenv)] [(ProcessName Contains ServiceHub) || (ProcessName Contains devenv)] ProcessName Count ProcessorNumber Depth [(Count>10 && (Depth >= -1) && (Count<=30) && (Count <= 30 || ProcessorNumber == 2))] Count ProcessorNumber Depth [(Count > 10 && (Count <= 30) && (Count <= 30 || ProcessorNumber == 2))] Count ProcessorNumber Depth
左侧面板包含跟踪中的所有事件。 其中包括 OS 内核收集的事件、.NET 运行时,以及收集数据时指示的任何其他事件。
由于事件类型的数量可能很大(通常为数十个),因此事件类型窗格顶部有一个“过滤器”文本框。 如果要查找特定事件,只需在此文本框中键入事件名称的某些部分,显示的列表将被筛选为在名称中某处包含键入文本的事件。您在此处键入的文本实际上是一个 .NET 正则表达式,这意味着您可以使用通配符(. 和 *),也许最重要的是 |运算符表示“或”。这使您可以快速过滤掉除一些有趣事件之外的所有事件。另请记住,Ctrl-A 将选择视图中的所有内容。
更新事件视图时,除了填充主列表框外,它还会生成事件计数的直方图,该直方图显示所选事件的频率如何随时间变化。由“开始”和“结束”文本框指定的时间间隔被划分为 100 个存储桶,并计算每个存储桶的事件计数,然后缩放此数字,使最大的存储桶表示 100%,并使用堆栈查看器的 When 列中使用的相同约定将此百分比转换为数字(或字母)。它显示在列表框的正上方。与“当”列一样,您可以选择此显示的一部分,然后使用“设置范围过滤器”命令 (Alt-R) “放大”。此外,当您更改直方图文本框中的选择时,PerfView 将计算开始和结束时间、事件总数和平均事件速率,并在状态栏中显示这些值。
下面是一些值得了解的内核和 .NET 事件
|
Windows Kernel/Thread/CSwitch - 每当线程获得或失去对物理 CPU 的使用时显示。 |
在开始收集之前,PerfView 需要知道一些参数。 它填充除要运行的命令之外的所有命令的默认值。因此,在常见情况下,您只需要填写命令即可运行(您使用的是“运行”命令)并按回车键开始收集数据。
无论您使用“运行”还是“收集”命令,都会在计算机范围内收集配置文件数据。 要收集配置文件数据,您必须具有管理员权限。 否则,PerfView 将尝试提升 (打开 UAC 对话框) ,并使用管理员权限重新启动自身。
PerfView 选择一组有用的默认 ETW 事件进行记录,这些事件允许进行常见的性能分析,但是,可以打开许多 ETW 事件。 以下是这些更高级事件中一些最有用的示例。
此选项往往对性能产生非常明显的影响(2 倍或更多)。此外,如果应用程序主动分配,则触发的事件速度如此之快,以至于即使使用 /BufferSizeMB 限定符将大小设置得非常大(例如 500Meg),事件也会丢失。由于这些原因,如果可能的话,通常最好改用 .NET SampAlloc 选项。
打开 .NET SampAlloc CheckBox 的开销远小于 .NET Alloc CheckBox。通常,开销为 10-20%(与 2 倍或更多不同),每分钟产生 200 Meg 的跟踪。这比打开 /threadTime 要贵一些,但要低到可以在生产环境中将其保留(尤其是在应用程序没有大量分配的情况下)。
请注意,这只影响在数据收集开始后启动的进程。这也可以通过 /DotNetAllocSampled 命令行选项激活。有关更多信息,请参阅 GC Heap Net Mem。
此选项中的事件称为“CallEnter”,并显示在“高级组”视图的“AnyStacks”视图中。最有可能的是,您希望通过选择“CallEnter”节点来筛选出视图中的所有其他事件>右键单击“包含项”>。
此选项往往对性能产生非常明显的影响(5 倍或更多)。如果应用程序运行大量代码(通用),则可能需要将 /BufferSizeMB 限定符设得非常大(例如 1000Meg)。即使这样可能还不够,此选项实际上仅适用于小型孤立测试。
有一个命令行选项 /DotNetCallsSampled,它的工作方式类似于 /DotNetCalls,但它对每个 997 调用进行采样,而不是对每个调用进行采样。这会将开销(和文件大小)减少 ~1000 倍,如果担心开销,则效果更好。
默认情况下,运行时不会禁用方法的内联。因此,您不会在跟踪中看到内联调用。还有一个命令行选项 /DisableInlining,它禁用内联,以便你看到每个调用。这会进一步减慢速度,因此只能在“小”场景中使用。
由于某些列表使用空格作为分隔符,如果在命令行上指定这些列表,则需要引用命令行限定符。
除了更高级的事件之外,还有一些您很少需要更改的高级选项。
您可以从下拉菜单中选择其中的几个选项,并根据需要修改计数。 目前,这些事件没有特殊视图,它们在“任何堆栈堆栈”视图中显示为 PMCSample 事件。因此,转到该视图并对此项目执行“包含项目”将允许您查看样品在哪个堆叠处采集。
提供程序浏览器是从 ...“其他提供程序”文本框右侧的按钮。提供程序浏览器允许用户检查可用的提供程序以及任何特定提供程序的可用关键字。
由于计算机范围内有许多可用的 ETW 提供程序,因此浏览器还允许将搜索筛选为仅与特定进程相关的提供程序。
虽然提供程序的名称及其关键字通常足以决定是否打开哪些事件,但您希望了解有关可能事件的更多信息并不罕见。这就是“查看清单”按钮的用途。许多提供程序注册一个称为清单的 XML 文档,该文档以相对精细的细节描述提供程序可以生成的所有事件。此清单中包括
ETW 数据收集的模型是在整个计算机范围内收集数据。此外,数据收集可能会超过开始收集的进程的生存期。虽然此特性很有用(它允许独立的启动和停止命令行命令),但它也意味着可能会意外地使 ETW 集合无限期地运行。PerfView 会在一定程度上确保在典型情况下停止数据收集,但是,如果 PerfView 异常终止,或者使用了命令行“启动”操作,则 ETW 数据收集可能会保持打开状态。Collect->Abort 命令就是为这种情况而设计的。它确保 PerfView 打开的任何 ETW 提供程序都处于关闭状态。
最后,还可以轻松地从命令行启动 PerfView 来收集配置文件数据。有关详细信息,请参阅从命令行收集数据。
内存收集对话框允许您选择用于收集 GC 堆数据的输入和输出,以及设置有关如何收集该数据的其他选项。
遗憾的是,普通 .NET 正则表达式的语法对于匹配方法名称的模式不是很方便。 特别是,'.'、'\'、'('')',甚至'+'和'?'都用在方法或文件名中,需要转义(或者更糟糕的是,用户会忘记他们需要转义它们,并得到误导性的结果)。 因此,PerfView 使用一组简化的模式来避免这些冲突。 模式是
这种简化的模式匹配用于 GroupPats、FoldPats、IncPats 和 ExcPats 文本框。如果您需要更强大的匹配运算符,可以通过在 ENTIRE PATTERN 前面加上 @ 来做到这一点。这向 PerfView 指示模式的其余部分遵循 .NET 正则表达式语法。
“查找”框中不使用简化的模式匹配。 为此,使用了真正的 .NET 正则表达式。
另请参阅简化模式匹配。
从根本上说,PerfView 探查器收集的是一系列堆栈。 每毫秒为计算机上的每个硬件处理器收集一个堆栈。 这是非常详细的信息,但由于“树”(许多不同组件使用的数百甚至数千个“帮助程序”方法的数据),很容易看不到“森林”(语义组件消耗不合理的时间)。 驯服这种复杂性的一个非常重要的工具是将方法分组到语义组中。 PerfView 提供了一种简单但非常强大的方法来执行此操作。
每个示例都由一个堆栈帧列表组成,每个堆栈帧都有一个与之关联的名称。 最初看起来像这样
具体而言,该名称由包含该方法的 DLL 的完整路径组成(但已删除文件名后缀),后跟“!”,后跟方法的全名(包括命名空间和签名)。 默认情况下,PerfView 只是从名称中删除目录路径,并使用该路径进行显示。 但是,可以改为要求 PerfView 将与特定模式匹配的方法组合在一起。 有两种方法可以做到这一点。
第一种形式是最容易理解的。 基本上,它只是搜索和替换所有帧名称。 任何与给定模式匹配的帧都将(完整地)替换为 GROUPNAME。 这具有创建组(与特定模式匹配的所有方法)的效果。 例如,规范
将匹配任何具有 mscorlib 的帧!Assembly:: 并将整个框架名称(而不仅仅是匹配的部分)替换为字符串 'class Assembly'。 这样做的效果是将类 Assembly 中的所有方法分组到一个组中。 使用一个简单的命令,您可以将特定类中的所有方法组合在一起。
与 .NET 正则表达式一样,PerfView 正则表达式允许你“捕获”字符串中与模式匹配的部分,并将其用于形成组名称。 通过使用 {} 将模式的各个部分括起来,您可以捕获该部分模式,然后可以使用 $1, $2, ...表示第一,第二,......捕获。 例如
表示匹配 ! 之前包含字母数字字符的任何帧,并将这些字母数字字符捕获到 $1 变量中。 然后,无论匹配什么,都用于形成组名。 这样做的效果是按包含样本的模块对所有样本进行分组(“模块级视图”)。
具有多个组规范很有用,因此组语法支持分组命令的分号列表。 例如,这是另一个有用的。
此规范中有两种模式。 第一个(蓝色)外观捕获了 !以及 (. 这将捕获 .NET 样式方法名称的“类和命名空间”部分。 第二种模式对 C++ 样式名称(使用 :: 将类名与方法名分开)非常相似。 因此,上面的规范按类对方法进行分组。 强!
另一个有用的技术是利用这样一个事实,即模块的完整路径名与组的匹配范围甚至比模块更广泛。 例如,由于 * 匹配任意数量的任意字符,因此模式
将具有将来自任何模块的任何方法分组的效果,该模块将 system32 作为其模块路径的任何部分作为“OS”。 这非常方便,因为通常这是人们想要的。 他们不希望看到操作系统内部方法的任何细节,他们希望将它们组合在一起。 这个简单的命令一举完成此操作。
当帧与组匹配时,它按组模式的顺序完成。 一旦发生匹配,就不会对该帧的组模式进行进一步处理(第一个帧获胜)。 此外,如果省略 GROUPNAME,则表示“不进行转换”。 这两种行为可以组合在一起,以强制某些方法不在组中。 例如,规范
强制所有模块使用模块级视图(红色分组模式),但是由于第一种(蓝色)模式,任何具有“myDirectory;在他们的路径中不按红色模式分组(他们被排除在外)。 这可用于创建“只是我的代码”效果。 除了位于“myDirectory”下的代码之外,每个模块的功能都组合在一起。 强!
到目前为止,这些例子是“简单组”。 简单组的问题在于,您忘记了有关您如何“进入”组的宝贵信息。 考虑将 System32 中的所有模块分组到前面考虑的名为 OS 的组的示例。 这效果很好,但有局限性。 您可能会看到,在操作系统中调用的特定函数“Foo”可以使其在操作系统中执行的任何操作都需要花费大量时间。 现在,只需查看“Foo”的主体就可以“猜测”正在调用什么操作系统函数,但这显然是一种不必要的痛苦。 收集的数据确切地知道输入了哪个操作系统功能,只是我们的分组已经剥离了该信息。
这是条目组要解决的问题。 它们就像普通组一样,但使用 => 而不是 -> 来表示它们是条目组。 条目组创建与普通组相同的组,但它指示分析逻辑将调用方考虑在内。 实际上,每个“进入组的入口点”都形成了一个组。 如果从组外部到组内部进行呼叫,则入口点的名称将用作组的名称。 只要该方法调用组中的其他方法,堆栈帧就会被标记为在组中。 因此,边界方法被单独保留(它们总是形成另一个组,但内部方法(在组内调用的方法)被分配给任何调用它的入口点组。
这非常符合人们通常的模块化概念。 虽然在某些情况下将操作系统中的所有功能分组为一个组是合理的,但按“公共外围应用”(操作系统的每个入口点的组)对它们进行分组也是合理的。 这就是条目组的作用。 因此,命令
将折叠所有操作系统功能,仅将其入口点保留在列表中。 这非常强大!
组可以是一个强大的功能,但通常仅通过查看模式定义并不能清楚地了解组的语义有用性。 因此,允许在实际组模式之前进行组的描述。 此说明用方括号 [] 括起来。 PerfView 会忽略这些描述,但是对于人类查看这些描述以了解模式的意图非常有用。
另请参阅简化模式匹配。
特定的帮助程序方法在配置文件中显示为“热”的情况并不少见。 您已经查看了此辅助方法,它与制作的一样高效。 没有办法让它变得更好。 因此,在配置文件中看到此方法不再有趣。 你希望此方法“内联”到其每个调用方中,以便向他们收取费用(而不是显示在帮助程序中)。 这正是折叠的作用。 “FoldPats”文本框只是一个要折叠的模式的分号列表。 因此,模式
将从跟踪中删除 MyHelperFunction,将其时间移动到调用它的人中(作为独占时间)。 它具有将 MyHelperFunction “内联”到所有调用方中的效果。
分组转换发生在折叠(或筛选)之前,因此可以使用组的名称来指定折叠。 因此,折叠规格
将在一个简单的命令中折叠所有操作系统功能(到它们的父级)。
一般来说,如果某个方法在视图中消耗的不超过总数的 1%,那么它通常只是“杂乱无章”地显示。折叠 % 文本框旨在消除此干扰。任何方法整体聚合非独占指标(即“Inc”列的 ByName 视图中显示的内容)都小于总指标的 1%,将被删除,并将其指标提供给其直接父级。
虽然将这个数字增加到一个很大的值(比如 10% 或更多)很诱人,但要强制大多数调用堆栈变得“大”,这通常会产生较差的结果。原因是 % 没有考虑节点的语义相关性。因此,折叠可能会将一个非常语义有意义的节点折叠成某个更高级别函数的“助手”。因此,通常最好选择“你不理解”的节点来折叠,这样你剩下的就是对你有意义的节点。
分组和折叠具有不影响跟踪中总样本计数的属性。样本不会被删除,它们只是被重命名或分配给另一个节点。完全排除节点也很有用。ExcPats 文本框是简化正则表达式的分号列表(请参阅简化模式匹配)。如果堆栈中的任何帧与此列表中的任何模式匹配,则会将其从视图中删除。模式不必与完整的帧名称匹配,除非它被锚定(例如,使用 ^)。图案在分组和折叠后匹配。
排除筛选的常见用途是查找应用中“第二大问题”的性能问题。 在这种情况下,你发现一个特定的方法(比如“Foo”)设计得很糟糕,你甚至知道如何修复它,但你也知道这不是你唯一的问题。 你想要的是找到下一个最重要的问题。 通过排除调用“Foo”的样本,您可以有效地模拟如果 Foo 是“完美”(不需要时间)程序的行为。 这通常是应用修复程序后程序外观的近似值。 因此,通过简单地排除这些样本,您可以寻找下一个性能问题,从而快速解决其中的许多问题。
默认情况下,事件是在计算机范围内捕获的,但通常只对某些示例感兴趣。例如,只对一个进程或一个线程感兴趣,或者只对一种方法感兴趣是很常见的。这就是 IncPats 文本框的作用。文本框的内容是以分号分隔的简化正则表达式列表(请参阅简化模式匹配)。堆栈必须至少与 IncPats 列表中的模式之一匹配,才能包含在跟踪中。模式不必与完整的帧名称匹配,除非它被锚定(例如,使用 ^)。图案在分组和折叠后匹配。
如前所述,使用 IncPats 文本框将分析限制为单个进程是很常见的。 使用“|”也非常有用(or) 运算符,以便您可以只包含两个(或更多)进程并排除其余进程。
“放大”到感兴趣的特定时间并过滤掉超出此范围的样本非常有用。 这是通过适当设置“开始文本框”和“结束文本框”来完成的。 这些范围是包含的(在两端),并且从跟踪开始表示为毫秒。 当然,您可以手动输入时间,也可以从显示屏的其他部分剪切和粘贴数字。 此外,如果您将两个数字粘贴到“开始”文本框中,它将设置开始值和结束值。还有其他一些不错的快捷方式可以设置时间间隔。
树节点的“第一列”和“最后一列”通常是有用的筛选范围。 要轻松做到这一点,只需选择两个框(通过拖动或按住“Ctrl”键,同时单击其他条目),选择两个单元格后,您可以右键单击并选择“设置时间范围”,这会将开始和结束时间设置为第一列和最后一列。您还可以通过将两个数字复制到剪贴板(选择两个单元格并按 Ctrl-C),然后将数字粘贴到“开始”文本框中来选择时间范围。此文本框足够智能,可以识别粘贴的值是一个范围,并将适当地设置“结束”时间。
根据“时间”列选择时间范围也非常有用。 为此,首先选择感兴趣的“时间”单元格。 这将导致视图底部的状态栏显示“何时”文本。 通过将鼠标拖动到字符上,突出显示感兴趣的区域(通常是成本较高的区域)。 然后将鼠标移出所选区域,右键单击并选择“设置时间范围”。 这会将“开始”和“结束”时间设置为您选择的区域。 您最终可能会重复此过程以进一步“放大”到某个区域。
如果堆栈查看器中查看的数据样本超过 1M,则响应速度会变得非常缓慢(需要 10 > 秒才能更新)。为了避免这种情况,某些堆栈源(最明显的是内存堆栈源)支持采样的概念。采样背后的基本思想是只处理每 N 个样本。因此,通过将采样文本框设置为 10,堆栈视图只需处理 1/10 的数据,因此速度应该快 10 倍。启用采样后,堆栈查看器会自动按采样率缩放视图中的所有计数(因此也缩放指标)。因此,生成的指标和计数与未采样时大致相同(您可以看到这一点,因为所有计数都是采样率的倍数。
通过在堆栈查看器右上角的“查找:”文本框中键入搜索模式,可以对视图中的名称进行文本搜索。Ctrl-F 将带您快速进入此搜索框。搜索模式使用 .NET 正则表达式,并且不区分大小写。搜索从当前光标位置开始,并一直环绕,直到搜索完所有文本。F3 键可用于查找模式的下一个实例。搜索完所有文本后,应用程序将发出哔哔声。之后的下一个 F3 重新开始。表达式的指定与布尔条件相结合,可以类似于在“要显示的列”文本框中筛选选择列。
可以编辑 GroupPats、FoldPats 和 Fold% 文本框以包含自定义模式。这些模式组合在一起可以保存为命名预设。
要创建新预设,请使用“预设”->“另存为预设”菜单项。如果 GroupPats 文本框包含描述(包含在 [] 中),则描述将作为预设名称提供。否则,将建议自动生成的名称。
所有创建的预设都将添加到所有活动 PerfView 窗口的“预设”菜单中。在“预设”菜单中选择菜单项以激活预设。预设的名称将显示在 GroupPats 文本框的 [] 中。预设在会话之间保存。预设 -> 管理预设菜单项允许编辑现有预设以及删除它们。
挂钟时间调查分为两起案件。 要么大部分挂钟时间由 CPU 主导(在这种情况下,CPU 调查将起作用),要么不由 CPU 时间主导,在这种情况下,您还需要了解正在消耗的阻塞(非 CPU)时间。 因此,进行挂钟调查的“困难”部分是了解阻塞时间。
阻塞时间调查本质上比 CPU 调查更难。CPU 调查相当简单,因为在大多数情况下,任何 CPU 使用率都是“有趣的”调查,无论它发生在哪里。因此,无论发生在哪里,对每毫秒的 CPU 施加相同的权重的简单算法是合适的。在某些情况下,这实际上并非如此。例如,如果多处理器计算机上有一个后台 CPU 密集型任务,则与该后台任务关联的 CPU 可能不是很有趣,因为它不会消耗“宝贵”资源,并且不在某些用户操作的关键路径上。因此,如果您正在调查此类应用程序上的 CPU,则需要一种方法来过滤掉此“后台”活动,以便您可以专注于“重要”的 CPU 使用。通常,这很容易做到,因为执行此类后台 CPU 活动的线程专用于后台活动(因此,您只需从这些线程中排除所有示例)。但是,想象一下,如果后台线程是一个“服务”,并且在其上安排了重要的前台 CPU 活动,并与空闲的后台活动交错。这将使分析变得相当困难。
这种糟糕的情况正是您在时间受阻时遇到的情况。 通常,有许多线程将大部分时间都花在阻塞上,而这些阻塞时间的大部分时间从来都不有趣,因为它不是关键路径的一部分。 但是,这些线程至少在某些时候会唤醒,并且它们的执行部分可能位于关键路径上(因此非常有趣)。 不幸的是,没有一种简单、通用的方法可以将“重要”阻塞时间(在关键路径上)与无趣的阻塞时间区分开来,而无需对程序的 INTENT 进行额外的“帮助”(注释)。 因此,进行阻塞时间分析的“诀窍”是使用特定于场景的机制来标记“重要”阻塞时间,并允许它与(大量)不重要的阻塞时间分开。
PerfView 必须了解挂钟时间或阻塞时间的视图称为线程时间视图。 这种观点基于这样的观察,即在任何时刻,每个线程都在做“某事”。 它可能正在消耗 CPU,也可能不是(我们将它定义为 BLOCKED)。 如果它被阻塞,可能是因为它在等待轮到它使用处理器(我们称之为 READIED),或者它可能正在等待其他东西(例如,等待 DISK 请求响应,或者 NETWORK 响应,或者等待某些同步对象(例如事件、互斥、信号量等)改变状态。 无论它在做什么,都有一个与之关联的堆栈。 因此,在每个时刻,每个线程都有一个堆栈,并且该堆栈可以用一个指标进行标记,该指标表示线程在该调用堆栈中消耗的时钟时间。 这是每个线程在系统上执行的操作的“完美”模型。
如果在收集对话框中设置“线程时间”复选框,或将 /ThreadTime 限定符传递给命令行,则 PerfView 将要求操作系统收集以下信息:
有了这些数据,我们就有了关于我们被封锁的地方的“完美”信息。 我们知道开始阻塞和结束的确切时间,因此可以将正确的时间归因于该特定堆栈。 我们还有花费 CPU 时间的大致信息。 如果我们得到一个样本(可能是 CPU 样本或上下文切换),我们可以将该堆栈归因于自上次采样以来所花费的时间(这又是一个上下文切换(例如,如果线程的 CPU 小于 1 毫秒)或另一个 CPU 样本(例如,如果自上次上下文切换以来超过 1 毫秒)。 因此,上面的事件我们可以很好地详细说明每个线程花费时间的确切位置。 有趣的是,您可以获得有关事物使用多少 CPU 时间的“完美”信息(因为您确切地知道线程何时开始消耗 CPU 时间以及何时停止消耗 CPU)。 唯一的缺陷是与 CPU 关联的堆栈只是一个采样。
上下文切换和 CPU 示例的这种转换是 PerfView 中“线程时间堆栈”视图的基础,也是了解挂钟时间(或阻塞时间)的首选视图。 与 CPU 堆栈视图一样,“线程时间堆栈”视图显示包含的“树”,它聚合了线程花费时间的所有这些堆栈。 在每个堆栈的底部(远离线程开始)端附加一个伪帧,该伪帧指示有关该堆栈的已知信息(CPU_TIME、DISK_TIME、HARD_FAULT(获取映射文件的磁盘时间)、NETWORK_TIME、READIED_TIME或BLOCKED_TIME)。 对于某些已知的东西(例如文件或网络端口,因此也会为它们插入伪帧。 通过这些标记,可以轻松地使用 PerfView 的折叠、分组和筛选功能来仅查看某些延迟原因。
从广义上讲,时钟时间调查包括以下步骤
总而言之,挂钟(或阻塞时间)调查总是从筛选开始,以查找“有趣的”挂钟时间(通常在单个线程上)。 在你到达这一点之前,你无法明智地解释“线程时间视图”,但在你找到有趣的时间之后,它就像 CPU 分析一样进行。
有时,确定阻塞时间的大小和调用堆栈足以了解特定的性能问题。 例如,分析应用程序的冷启动时间就属于这一类,因为了解为什么阻塞时间如此之长是很清楚的(需要磁盘读取),因此唯一的问题是这些操作有多长时间以及发生在哪里(是什么堆栈导致了它们)。 但是,在其他情况下,问题在于理解为什么延迟会如此之长。 例如,如果一个线程在等待锁时被阻塞,那么有趣的问题是,为什么其他线程保持锁的时间这么长? 要回答这个问题,您需要确定哪个线程保持锁定。 像这样的问题就是 ReadyThread 事件帮助回答的问题。
打开 /ThreadTime 事件时,不仅会打开上下文切换事件,还会打开 ReadyThread 事件。 当一个线程导致另一个线程从被阻止更改为可运行(即,使线程准备好运行)时,将触发 ReadyThread 事件。 因此,如果线程 A 正在等待线程 B 拥有的锁,则当线程 B 释放锁时,它会使线程 A 准备好运行。 在此示例中,当 ReadyThread 事件触发时,它会记录线程 A 和 B 以及线程 B 的堆栈。 粗略地说,READYTHREAD 记录了线程 B 导致线程 A 唤醒的事实。
PerfView 有一个特殊的视图,用于显示 READYTHREAD 信息,称为“线程时间(使用 ReadyThread)”视图。 此视图的工作方式与“线程时间”视图类似,但此外,线程阻塞的每个堆栈都会“扩展”,并带有附加帧,这些帧会告诉您唤醒线程的线程和堆栈。 这些额外的框架以“(READIED_BY)”为后缀,因此您知道您可以轻松地看到这些不是普通的框架(如果您愿意,可以将它们折叠起来)。 在线程 A 等待锁并被线程 B 释放锁唤醒的示例中,您会看到
这清楚地表明,在阻塞“X!LockEnter”后,线程被线程 B 调用“X!LockExit”唤醒。
如果您还没有阅读了解线程时间的基础知识,那么现在应该阅读。本节以这些基础知识为基础。
如果需要执行异步或并行操作,强烈建议使用 .NET System.Threading.Tasks.Task 类来表示异步操作完成后的并行活动或线程的“延续”(C# 中的“await”功能使用 Tasks)。 任务对 PerfView 的价值在于,此类在创建任务 (以及已创建任务的 ID) 、调用任务正文时 (以及任务的 ID) 以及任务的正文完成 (再次与 ID ) 一起记录事件。 这在两个重要方面帮助我们
“线程时间(含任务)”视图正是这样做的。当线程调用任务创建方法时,此视图会在此时插入一个伪帧,指示已调度任务,然后在该点插入该任务正文的所有事件。下面是一个示例
在此示例中,名为“DoWork”的“Main”程序具有代码
此调用会导致另一个线程(在本例中为线程 848 启动,并开始执行正文(委托 {...})。 此“内联委托”代码称为匿名委托,编译的 C# 会为其生成名称(在本例中为“c__DisplayClass5.b__3'),它完成工作(请注意,PerfView 的“转到源”(Alt-D) 选项在这一点上非常方便,可以确切地查看此代码是什么)。
这里重要的部分是,从源代码级别来看,很自然地认为在这个匿名委托上花费的任何成本(时间)都应该“收费”到“DoWork”,因为该代码导致该委托实际运行(在不同的线程上)。 这正是“线程时间(包含任务)”视图的作用。 如果应用程序使用 Tasks,则应使用此视图。
从本质上讲,服务器调查通常与响应时间有关。因此,要进行服务器调查,您希望将导致此响应时间更长的所有成本汇总到显示中。这正是具有启动-停止任务视图的线程时间的作用。
这最好通过示例来说明。这是使用“PerfView /threadTime collect”监视的 ASP.NET Web 服务器的示例。由于我们使用 /ThreadTime 参数,因此会收集有关上下文切换和任务的信息,从而允许显示“线程时间”视图,包括“线程时间(使用 StartStop 任务)”显示。下面是打开此视图并专注于 W3WP 进程(即 Web 服务器进程)的结果。
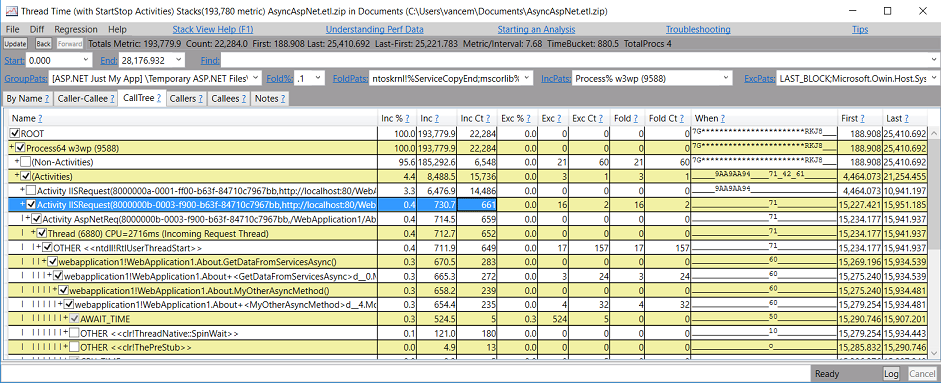
在树的顶部,我们看到了流程节点,但随后所有成本立即被分为两部分,与某些启动-停止活动相关的内容以及其他所有内容。因此,这使您可以快速关注可能感兴趣的线程时间。
在“活动”节点下,您可以看到所有“顶级”启动-停止活动,这些活动按成本(即归因于该活动的线程时间)排序。在上面的视图中,我们打开了“IISRequest”活动(具有特定的 ID 号和 URL),该活动恰好具有 730.7 毫秒的线程时间。此 IISRequest 活动恰好导致 AspNetReq 活动的另一个嵌套的 Start-stop 对,因此显示,从那里显示与 AspNetReq 活动关联的所有堆栈。在此示例中,我们可以通过用户代码看到对 MyOtherAsyncMethod 方法的调用堆栈,该方法执行需要 524.5 毫秒的“await”)
希望您能立即看到此视图的有用性。基本上,它占用了与语义相关事物(某人在代码中检测的启动-停止任务)相关的所有线程时间,并根据因果关系显示堆栈(因此,如果执行跃点线程“跟随”它,则事件)。因此,确切地看到时间花在哪里变得微不足道。
典型的策略是立即选择“(活动)”节点,右键单击 -> Include Item,这将排除所有非活动线程时间。这在大多数情况下效果很好,但请记住,一些重要的成本可能在这个(非活动)节点中,特别是像 GC(在服务器或后台 GC 中)这样的事情,或者任何非线程池线程确实工作但从未记录过启动和停止事件。这就是 PerfView 不会隐藏这一点的原因,但通常你首先查看活动,只有在你被引导到那里时才向外看。通常,如果您要过滤以仅查看非活动而仅查看CPU_TIME,则查看该组中“有趣”的内容。
需要注意的是,显示的是 STILL 线程时间,而不是挂钟时间。因此,如果存在并发性,则总指标加起来很可能超过经过的挂钟时间。这很容易确定是这种情况(因为您将看到多个线程作为活动的子线程),您甚至可以看到重叠(通过查看每个子线程的“时间”列)。尽管如此,这仍然是需要注意的事情。有关详细信息,请参阅了解线程时间。
线程时间也可能小于经过的挂钟时间。这应该是一个更罕见的情况。当代码导致工作发生,但没有使用已检测的机制来检测另一个线程上的工作是由当前线程引起的时,就会发生这种情况。因此,当前线程可能会返回到线程池 (此时它的时间不再归因于活动) ,但由于 PerfView 不知道另一个线程上的工作,因此它无法正确地将该时间归因于活动 (它最终位于非活动节点) 下。因此,请求的线程时间可能存在“间隙”。PerfView 尝试使用名为“UNKNOWN_ASYNC”的伪节点来填补这些空白,以便视图中的代价永远不会小于用于排序目的的挂钟时间,但有时 PerfView 的算法并不完美。然而,无论哪种情况,都很难确定在这些间隙中发生了什么。希望这根本不会发生在你身上......
通常,.NET Framework 中的“标准”检测会为您提供良好的“启动”活动(如上面的 IISRequest 和 AspNetReq 所做的那样)。但是,如果这些还不够,您可以定义自己的启动-停止活动。如果代码在 .NET Framework V4.6 或更高版本上运行,则添加将显示在此视图中的新启动-停止活动是微不足道的。有关执行此操作的详细信息,请参阅 EventSource 活动。在收集数据时,您需要使用 /Provider=*YOUR_EVENT_SOURCE_NAME 打开事件,此视图将自动合并它们。
PerfView 还可用于执行非托管内存分析。通常,内存调查的第一步(无论是托管内存调查还是非托管内存调查)都是使用免费的 SysInternals vmmap 工具等工具来确定进程的内存构成。该工具可以将当前的内存使用情况分解为六类,包括
根据其中哪一个是大的(因此很有趣,你以不同的方式攻击它。如果映射的 DLL 或 EXE 是问题所在,则需要加载较少的 DLL 或 EXE。PerfView 的“图像加载堆栈”将显示加载 DLL 的位置。如果问题出在 GC 堆上,则需要按照“何时关注 GC 堆”中所述进行 GC 堆调查。如果问题是最后两个问题之一,则本部分将告诉您如何深入了解该问题。
最后,进程中的所有内存要么被映射(例如 DLL 或 EXE),要么由 Windows VirtualAlloc API 分配。 PerfView 允许你通过选中高级收集对话框中的“虚拟分配”复选框,在每个 VirtualAlloc 调用(以及每个 VirtualFree 调用)上收集堆栈跟踪。 VirtualAlloc 旨在用于分配大量数据(实际上最小大小为 64K),因此打开此选项不太可能影响应用的性能,因此请随意执行此操作。 然而,正是因为 VirtualAllocs 很少被调用(通常是当另一个分配器需要更多内存时),所以这些信息通常是“粗略的”,并且仅在用户代码直接调用此 API 时才有用(这是不寻常的)。
更常见的是,您会注意到 VMMAP 中的显示中的“堆”条目很大,因此您需要钻取到操作系统堆中。 为此,我们需要在每次发生操作系统堆分配或空闲时收集数据。 这更为常见。 事实上,它是如此普遍,以至于操作系统没有提供一种在系统范围内打开它的方法(这将是太多的数据),相反,在集合对话框的高级部分有两个对话框。
使用这两种技术之一,您可以为感兴趣的进程打开操作系统堆事件。 (可选)还可以打开 VirtualAlloc 事件。
完成此操作并收集数据后,您将获得以下视图
这两个视图的工作方式相同。跟踪中的每个分配都会被赋予与分配的字节数相等的权重。每个空闲都被赋予负权重和分配的调用堆栈(这样它们就可以完美地“抵消”)。无法与整个跟踪中的分配匹配的释放将被忽略。在此之后,PerfView 将像处理任何其他基于堆栈的数据一样对待堆栈。它只考虑与其筛选器匹配的样本并显示结果。请注意,这意味着 VALUES 可以为负数。如果你选择一个只发生自由的时间愤怒,那么你会得到一个负数。基本的不变性是,视图显示所选范围的 NET 内存分配。由于指标现在可能为负数,因此“时间”列可能需要显示负数。这些字母使用小写字母显示(有关详细信息,请参阅“当列”)。
请注意,这意味着,如果理论上显示程序的总执行量,则应看到值为 0(您释放了分配的所有内容)。 在实践中,这是不正确的,但事实是,您通常对进程终止前使用的 FINAL 内存不感兴趣,而是对 PEAK 内存分配感兴趣。 为此,您需要找到内存分配达到峰值的时间。
您可以通过转到“CallTree View”并选择 When 列作为层次结构的根来执行此操作(大致)。拖动 when 列的区域时,PerfView 将计算拖动区域中的净值和峰值指标。因此,通过拖动,您可以快速确定峰值的位置。通常,您只需要点击“设置范围”(Alt-R),现在您就有了建立到峰值内存使用量的时间区域。
您还可以通过选择任何特定操作的时间范围来轻松调查该操作的净内存使用情况。所有正常的过滤、折叠和分组运算符都有效。对于内存情况。最后,通过打开两个视图,您可以使用 Diff 功能对应用程序的两次运行进行分析。
目录大小菜单项将生成一个 *.directorySize.perfView.xml.zip 文件,该文件是目录中所有文件大小的分层总和(递归)。因此,它是一个很好的工具,可以确定什么占用了磁盘驱动器上的磁盘空间并“清理”了价值较低的文件。
选择此菜单项将打开一个目录选择器,用于选择要分析的目录以及将保存收集的数据的文件的名称。选择后,PerfView 将对该目录进行递归扫描,这需要一段时间。当它完成时(对于大型目录可能需要一段时间),它将自动打开它生成的数据文件)。以后可以随时重新打开该文件,只需在 PerfView 的主树视图中单击它即可。
目录大小的“when”字段的工作方式与大多数性能数据略有不同。对于每个数据文件,其“时间戳”是从收集数据到上次修改的天数(可以是小数)。因此,通过选择从 0 到 7 的时间范围,您将看到不到一周前修改的所有文件。此信息对于查看数据的“旧”程度非常有用(这通常有助于确定是否保留数据)。
选择“大小 -> 图像大小”菜单项将打开一个对话框,用于指定 DLL 或 EXE 来执行大小分析。此外,它还允许您设置保存结果数据的输出文件的名称。该对话框将从输入文件名派生输出文件名,通常此默认值很好。
图像大小菜单项将生成一个 .imagesize.xml 文件,该文件描述了 DLL 或 EXE 文件的大小细分。它通过在其 PDB 文件中查找 DLL/EXE 的每个符号并为文件的每个块使用这些名称来实现此目的。它还查找从文件的一部分到另一个部分的引用(例如,内存 blob 中的指针或指向其他内存 blob 或汇编代码的汇编代码)。由于这些引用可以形成任意依赖关系图,就像 GC 堆对象形成依赖关系图一样,因此 PerfView 以与 GC 堆非常相似的方式显示此数据。与 GC 堆一样,“When”、“First”和“Last”列不显示时间,而是表示加载时特定项在虚拟地址空间中的位置的地址。因此,您还可以使用它来了解加载时文件中不同符号的位置。
如前所述,默认情况下,PerfView 会尝试在 DLL 中创建项的“GC 堆”,如果一个项引用另一个项,它将具有从引用方到被引用对象的链接。但是,此行为可能会干扰某些分析。.特别是,如果您使用“include pats”或“exclude pats”文本框,它将包含或排除 ON THE WHOLE PATH。当这不是你想要的时,解决问题的一个简单方法是“展平”图形。
展平一组节点需要一组节点,并返回一个新的“GC 堆”,其中
图像大小报告中使用的许多名称都是符号名称,这些符号名称与源代码中的名称有直接关系。但是,其他名称描述可移植可执行文件 (PE) 格式的实体,这些实体需要准备要运行的 DLL/EXE 中的代码/数据。在这里,我们描述了其中一些可能在输出中突出显示的内容。
其他名称与 .NET 运行时本机文件格式相关联。
通过选择“大小 ->IL 大小”菜单项,可以对 .NET 中间文件 (IL) 中的内容进行分析,这是 .NET 编译器(如 C# 和 VB)创建的内容。它将生成一个 .gcdump 文件,该文件在 IL 文件中生成类型、方法、字段和其他结构的图形,其中图形的每个节点都表示它在文件中的大小,节点之间的弧线是从一项到另一项的引用。因此,您可以像 GC 堆中的对象一样进行依赖关系分析(哪些事物指的是其他事物)。
“Size -> IL Size”菜单项将打开一个对话框,用于指定要对其执行大小分析的 DLL 或 EXE。此文件必须是包含 .NET IL 的 DLL 或 EXE(例如 .NET 编译器的输出)。此外,它还允许您设置保存结果数据的输出文件的名称。该对话框将从输入文件名派生输出文件名,通常此默认值很好。
图像大小菜单项将生成一个 .gcdump 文件,该文件描述了 IL 文件中类型、方法、字段和其他项目的细分。它的工作方式与 GC 堆分析或本机图像大小分析大致相同。
菜单项仅允许您在为 IL 代码创建节点弧图时指定一个 IL 文件。此文件之外的任何引用都不会遍历,而只是标记为特殊的“外部引用”节点。有时选择一组 IL 文件(例如,代表一个完整的应用程序)会很有用,这些文件会被遍历,只有当您离开该组时,您才会使用“外部引用”节点。您可以使用“ILSize.ILSize”用户命令执行此操作。因此,命令
将创建一个包含 File1.dll、File2.dll 和 File3.dll 的 GC 堆,就好像它们是一个文件一样。
通常,跨多个跟踪分析一个程序的性能很有用。这些跟踪可能表示各种方案中的一个大型项目,或者表示多个程序正在使用的公共库的行为。PerfView 支持用于此类多方案分析的多种功能。
同时分析多个场景(数据文件)时,一个主要挑战就是要处理的数据量。 单个场景通常可以有一个 100 兆字节的 ETL 文件,如果您有 100 个这样的场景,您现在正在谈论要处理的 10-100 GB 的信息。 因此,该过程旨在尽快减少数据量并保持这种“精益”形式,以便控制查看时的数据量。 因此,使用多个多个方案有两个主要步骤
以下是有关执行这些步骤的更详细说明。
同时查看多个数据文件的第一步是将数据预处理为“场景集”。您可以使用“SaveScenarioCPUStacks”用户命令执行此操作(目前仅支持 CPU 采样聚合)。您可以使用“File->UserCommand”菜单项从 PerfView GUI 运行它,也可以通过执行以下命令从命令行运行它
该 SaveScenarioCPUStacks 命令采用一个参数。此参数可以是目录名称(如上例所示),也可以是 XML 配置文件的路径。
如果传入目录, SaveScenarioCPUStacks 将以“自动”模式运行。它将处理在目录(或任何子目录)中找到的所有 ETL 和 ETL.ZIP 文件,使用启发式方法自动检测跟踪感兴趣的进程。用于选择感兴趣过程的启发式方法是
通常,这种启发式方法效果很好,但是,如果您需要控制运行方式 SaveScenarioCPUStacks ,则可以传入一个 XML 配置文件,以便您可以很好地控制 ETL 文件的处理。下面是一个示例 XML 配置文件:
如您所见,配置文件由根元素组成,根 ScenarioConfig 元素包含一个或多个 Scenarios 元素。每个 Scenarios 元素都设置了属性,用于控制方案的处理方式:
files 属性是 Scenarios 元素的唯一必需属性。此属性的值是要匹配的文件的通配符模式。与此模式匹配的所有文件都将进行预处理,并包含在输出方案集中。(相对路径是相对于包含 XML 配置文件的目录的路径。name 属性控制方案的名称,因为它显示在 GUI 中。这可以包含 $ .NET Framework 文档中指定的 -substitution。通配符模式中的每个 * 都将转换为一个捕获组,这将允许其与 $ 数字替换一起使用。(例如,模式中的第一个 * 可以称为 “ $1 ”。process 属性允许您覆盖跟踪的感兴趣进程检测逻辑。此属性的值应为要包含的进程的名称(不带任何 .exe 文件扩展名)。如果使用“*”作为进程名称,则跟踪中的所有进程都将处理到 perfView.xml.zip 文件中。与“name”属性一样,您可以在此属性中使用 $1,该属性将替换为相应的捕获组。start 和 end 属性允许您从匹配的跟踪中设置感兴趣的时间范围。在处理的输出中,time start 的事件将在 0 时发生,并且时间范围之外的任何事件都将被丢弃
运行 SaveScenarioCPUStacks 命令的结果是以下输出文件。
*.perfView.xml.zip 文件。仅当它们不存在,或者其对应的 ETL 跟踪数据较新时,才会生成这些数据,但如果它们是最新的,则不会对该文件执行任何操作。*.scenarioSet.xml 文件。此文件对于查看步骤 2 中的数据是必需的。
如果您愿意,还可以生成自己的 scenarioSet.xml 文件。scenarioSet 文件类似于方案配置文件,但属性略有不同。下面是一个示例 scenarioSet 文件:
如您所见,它基本上是一个文件模式列表(指示应包含 ScenarioSet.xml 文件的目录(或任何子目录)中的哪些文件),以及允许您获取该文件名并将其转换为方案名称的模式。 您可以创建自己的 XML 文件,以创建某些数据的有趣子集。
处理方案数据后,可以继续查看它。为此,请使用主视图中的树视图浏览到生成的 scenarioSet.xml 数据文件,然后双击将其打开。
在大多数情况下,这是您在单个 ETL 文件上使用的熟悉的堆栈查看器,主要区别在于来自特定数据文件(场景)的每个堆栈在最顶部都有一个新的伪帧,用于标识示例来自的场景。 因此,堆栈属于线程,属于进程,属于场景。 堆栈查看器的其他所有内容都与在单场景情况下一样工作。 堆栈视图看起来就像同一台计算机上同时显示每个方案一样。
除了每个堆栈的新“顶部”节点外,查看器还具有一些仅在多场景情况下可见的增强功能。 您将看到:
就像“when”列允许您为视图中的每一行看到一个小图形一样,该小图形在时间上将样本显示为函数(直方图),而“which”则向您显示具有样本参与该行的方案的直方图。 因此,您可以快速确定该行的成本是否在方案中均匀分布,或者是否只有少数方案对成本有贡献。
which 字段具有许多与之关联的方便功能。
PerfView 使用内置于 Windows 中的 Windows 事件跟踪 (ETW)Windows (ETW) 工具来收集分析信息。此基础结构不会自然地为数据创建单个文件,而是将来自 OS 内核的数据与其他事件隔离开来。因此,生成的“原始”数据由两个文件组成(一个只是 etl,另一个是 .kernel.etl)。此外,这些文件缺少在另一台计算机上完全解码文件所需的一些信息(最值得注意的是,操作系统内核名称到 NTFS 文件名的映射以及允许明确查找符号信息 (PDB) 的符号服务器“密钥”)。如果您在收集数据的同一台计算机上使用数据,则这些限制都不是问题,但如果您希望将其传输到另一台计算机,则应首先合并数据。
合并是将 .kernel.etl 合并到主 .etl 文件中的过程。 此外,还收集了缺少的特定于系统的信息,并将其放置在 .etl 文件中。 结果是可以将单个文件复制到另一台计算机进行分析。 此过程可能需要相当长的时间(10 秒),这就是 PerfView 默认不执行此操作的原因。 您可以通过以下方式执行合并
合并文件后,您只需将单个文件复制到另一台机器上即可进行“离线”分析。 但请注意,虽然 ETL 文件包含 .NET 运行时代码的符号信息,但它不包含非托管代码的符号信息。 因此,如果查看非托管代码的符号名称很重要,则需要确保进行分析的计算机有权访问包含此信息的 PDB 文件。
合并在收集数据的计算机以外的计算机上查看 ETL 文件所需的操作。但是,这并非适用于所有情况。虽然生成的合并文件包含查找符号信息(用于堆栈跟踪)的所有信息,但它并不能保证符号信息可用。具体而言,在收集其进程使用 .NET 运行时的跟踪时,必须引用托管代码(如果是 NGENed)的本机代码映像(NGEN 映像)的符号信息(PDB 文件)。这些 NGEN Pdb 不是 IL 映像的 PDB 文件(由 CSC.exe 或 VBC.exe 等 IL 编译器创建的内容)。NGEN PDB 由 .NET Framework 附带的 NGen.exe 命令生成,并且只能在生成 NGEN 映像的计算机上可靠地生成。
作为 ZIPPing 过程的一部分,PerfView 将查找 ETL 文件中的所有地址,并确定使用了哪些 NGEN 映像,并在必要时为这些映像生成 PDB 文件。然后,它会将 ETL 文件以及任何 NGEN PDB 压缩到一个 ZIP 文件中,现在可以在任何计算机上查看该文件(PerfView 知道如何自动解压缩这些文件)。
另请参阅通过生成 PerfView 扩展来实现高级自动化的 PerfView 扩展。
另请参阅命令行参考,以获取可在命令行中使用的选项的完整列表
PerfView 旨在使你能够使用批处理文件或其他脚本自动收集配置文件数据。三种可能的情况是:
在第一种情况下,您可能希望使用“run”或“collect”命令
“run”命令会立即运行该命令并启动堆栈查看器。 如果程序易于启动并且可以运行完成,则这是首选选项。 但是,有时很难做到这一点(应用程序是服务的一部分,或者由复杂的脚本激活),然后您可以使用“collect”命令启动系统范围的收集。
默认情况下,“collect”命令执行“rundown”,其中要正确解码在分析之前收集的符号信息的信息将停止。 此操作可能相对昂贵(只需几秒钟,并将文件大小增加 10 秒 Meg)。 当进程关闭时,自然会提供此信息,但“collect”命令不知道您是否关闭了感兴趣的进程,因此它会执行纲要。 如果您知道感兴趣的进程已退出,则 rundown 毫无意义,可以通过指定 /NoRundown 限定符来避免。 此选项可以节省时间和文件大小。
默认情况下,PerfView 假定你希望立即查看收集的数据,但如果收集数据的人(例如测试人员)不是分析数据的人(例如开发人员),则我们希望禁止查看者。 这就是 /noView 限定符的作用,它适用于 'collect' 和 'run' 命令。 因此
将打开日志记录并运行给定的命令。它还将合并该文件,假设该文件可能会从当前系统中移出。但是,它仍然会调出 GUI,并且在完成后不会自动退出(以便用户可以对任何故障或消息做出反应,并且是“collect”命令所必需的,以便用户可以指示何时应停止收集)。
另请参阅命令行参考,以获取可在命令行中使用的选项的完整列表
/NoView 在难以完全自动化数据收集(在 GUI 应用中测量临时方案)的地方很有意义。 但是,对于全自动收集,您根本不需要 GUI。 这就是 /LogFile 限定符的用途。 通过指定此限定符,可以指示不应打开 GUI,并且程序应在命令行上运行命令后退出。 本应在 GUI 中报告的任何错误消息都会附加到日志文件中(我们附加,以便你可以将同一文件用于多个 PerfView 命令。 PerfView 进程的退出代码将指示收集是成功还是失败,日志文件将包含详细的诊断消息。
请注意,/LogFile 限定符将禁止显示 GUI,但如果指定了“Collect”命令且未提供 /MaxCollectSec 限定符,则不会禁止生成控制台。原因是如果没有 /MaxCollectSec=XXX,Collect 命令可能会永远运行,并且您将无法完全停止它(您必须终止该进程)。如果要使用 /LogFile 和 Collect(因为希望使用 /StopOn* 限定符),并希望禁止显示任何控制台,则可以通过指定一个非常大的 /MaxCollectSec 值来实现此目的。
除了 /logFile 限定符之外,最好还将 /AcceptEula 限定符应用于调用 PerfView 的脚本。默认情况下,首次在任何特定计算机上运行 PerfView 时,它会显示一个弹出窗口,要求用户接受使用协议 (EULA) 。这对脚本来说可能是个问题,因为它需要人工交互。若要避免这种情况,可以在以无提示方式执行此操作的命令行上使用 /AcceptEula 限定符。
因此,/logFile 和 /AcceptEula 限定符的典型用法是命令
从脚本(无 GUI)运行“教程.exe”。 如果需要在系统范围内收集(要使用“collect”而不是“run”),则存在问题,因为 PerfView 不知道何时停止。 有两种方法可以解决这个问题。 第一种是使用“/MaxCollectSec”限定符。 例如,以下命令将收集 10 秒,然后退出。
如果您希望通过时间限制以外的其他方式控制停止,您还可以使用“开始”和“停止”和“中止”命令。
这些旨在在脚本中使用。第一个将开始记录,即使在程序退出后也保持打开状态。第二个停止日志记录。如果可以,应避免使用它们(请改用 collect /MaxCollectSec)。原因是,如果脚本在启动和停止命令之间失败,日志记录可能不会停止,并且将“永远”运行。因此,在使用这些产品时需要格外小心。“abort”命令旨在帮助确保 PerfView 不会进行日志记录。它应该在你知道 PerfView 不应运行的位置调用,并确保它确实没有运行。您应该在使用“start”命令的脚本中自由使用它。
正常的 Windows 事件跟踪 (ETW) 日志记录通常非常有效 (通常< 3%) 但是,在跟踪完成后,PerfView 通常会执行相对昂贵的操作来打包数据 (包括合并、NGEN 符号创建和 ZIP 压缩) 。显然,这些操作可能会使用可能会减慢机器上运行的任何其他操作的资源。
如果在命令行上将 /LowPriority 选项传递给 PerfView,则 PerfView 将以较低的 CPU 优先级执行这些操作。这可以显著减慢打包数据所需的时间,但可以最大程度地减少对系统的影响。
最好将容器视为轻量级虚拟机。有关 Windows 容器的更多背景信息,请参阅 Windows 10 上的 Windows 容器。特别是,Windows 支持称为“Windows Server 容器”的轻量级容器,其中内核在计算机上运行的所有容器之间共享。此类容器与名为 Docker 的工具结合使用,该工具允许您在虚拟化环境中创建操作系统映像并运行应用程序。
理想情况下,容器应该与使用 PerfView 无关,因为容器是一种 Windows 操作系统,而 PerfView 只是运行在那里的 Windows 应用程序。这基本上是正确的,但有一些差异需要考虑。
因此,PerfView 在容器中工作,但需要确保你拥有足够新的操作系统版本,并且使用自动收集中的技术在不使用 GUI 的情况下收集数据。
一个例子胜过一千个解释,所以这里有一个例子。首先,您需要从 Web 设置安装适用于 Windows 的 Docker。网上有很多很好的教程。设置 docker 后,您可以执行以下操作
这将拉下 Windows Server Core 的 1803 版本(约为 5GB)并在其中运行“cmd”命令。显然,您也可以拉下更高版本(1803 是 RS-4 版本,于 2018 年 4 月发布)。重要的是它是 RS-3 或更高版本。结果是 C> 命令提示符。
此时,可以将 PerfView 复制到容器中(例如,'net use \\SomeShare\SomeSpot)。复制 PerfView 后,可以执行以下操作
这将导致 PerfView 与控制台断开连接,并将任何诊断记录到 out.txt。最终,此命令将以正常方式创建 PerfViewData.etl 文件。您可以执行“键入 log.txt”来查看运行过程中的进展情况。如果将此命令放在批处理文件中,则它不会与控制台分离,因此在收集完成之前,批处理文件不会继续。因此,可以创建一个调用 PerfView 的批处理文件,然后将生成的文件复制到某个位置。如果希望让批处理文件开始收集,在监视时启动某些操作,然后停止它,还可以使用“start”和“stop”PerfView 命令而不是“collect”命令。关键是它的工作方式与普通窗口一样,PerfView 非常灵活。你几乎可以做任何事情。
windowsservercore docker 映像是 Windows 的一个相当完整的版本。特别是,它有一个完整的 .NET 运行时,这是 PerfView 需要运行的。Microsoft还支持更小的Windows的Docker映像,称为microsoft/nanoserver(300 MB,而不是5GB)。此操作系统支持 ETW,因此理论上可以在其上收集 PerfView 数据,但它没有桌面运行时,因此 PerfView.exe 工具本身无法运行。这就是“PerfViewCollect”工具的用途。
PerfViewCollect 是 PerfView 的一个版本,它已剥离其 GUI(它仅执行收集),并使用 .NET Core 运行时生成。生成 .NET Core 应用程序时,可以将其生成为独立应用程序,这意味着应用程序附带运行它所需的所有 .NET 运行时和框架 DLL。因此,您只需要基本的操作系统功能,特别是它将在 NanoServer 上运行。
目前,我们不会创建 PerfViewCollect 的二进制分发,它必须从 https://github.com/Microsoft/perfview 的源代码生成。若要生成,但是不需要 Visual Studio,只需要 .NET Core SDK,因此该过程是
最后一个命令会将 PerfViewCollect 应用程序生成为独立应用程序。该工具会告诉你它的位置,但它应该位于 src\PerfViewCollect\bin\Release\netcoreapp3.1\win-x64\publish 中。该工具是该目录中的 PerfViewCollect.exe。可以执行 PerfViewCollect /?获取一些帮助(但它将与 PerfView.exe 的命令行帮助完全相同)。
如果将此目录复制到纳米服务器,则也应该能够在那里运行 PerfViewCollect.exe,因此可以执行命令
在 Window nanoserver 上收集数据。
自 2018 年 10 月(或更早版本)起存在已知问题。基本上,问题在于作为容器中操作系统一部分的DLL(例如内核,ntdll,kernelbase等)最终使用HOST路径而不是CONTAINER路径。这没什么大不了的,除了 DLL 加载事件不包含用于在 Microsoft 符号服务器上查找 DLL 的符号文件的特殊唯一标识符。通常,作为准备(合并)要从系统复制的文件的一部分,这些唯一 ID 将添加到跟踪中。但是,由于这是在容器中完成的,并且事件具有 HOST 路径,因此执行此操作的逻辑将失败,因此 system.DLL 没有唯一 ID。这意味着 PerfView 无法查找符号名称。
有一个解决方法。如果获取正确的符号文件 (PDB) 并将其放在目录中,并使用“文件->设置符号路径”来包含此目录,并将 /UnsafePDBMatch 选项传递给 PerfView,则它应该可以正常工作。
有多种方法可以获取正确的符号文件,但一种方法是在容器中使用调试器,并要求调试器加载必要的系统文件。然后转到调试器放置它们的位置。
另请参阅命令行参考,以获取可在命令行中使用的选项的完整列表
PerfView 具有一些功能,这些功能专门用于收集有关生产工作负载的数据,以诊断仅在实际负载下发生的性能问题。我们已经看到了 /noView 选项,该选项指示在数据收集完成后,PerfView 应直接退出 (而不是尝试显示数据) 。还有其他几个有用的命令行选项可用于生产监视。首先是 /MaxCollectSec:N 限定符。命令
将指示 PerfView 最多应收集 20 秒。因此,此命令不需要用户交互即可收集数据样本。由于还提供了 /logFile 选项,因此有关集合的任何诊断信息都将发送到“collectionLog.txt”。因此,这可以通过单个命令行命令在服务器计算机上完全自动收集数据。
/MaxCollectSec 限定符可用于立即收集示例。但是,服务器遇到间歇性性能问题(例如,高 CPU 或高 GC 使用率等)的情况并不少见。因此,需要的是能够监控服务器,并且仅在发生“有趣”的事情时捕获样本。这就是 /StopOnPerfCounter 选项的用途。/StopOnPerfCounter 限定符的基本语法是
其中 CATEGORY:COUNTERNAME:INSTANCE 指示特定的性能计数器(遵循 PerfMon 使用的相同命名约定),OP 是 < 或 >,NUM 是数字。例如
指示 PerfView 应收集数据,直到“.NET CLR 内存”类别的“GC 中时间百分比”的 _Global_ 实例(表示系统上所有进程的所有 GC 堆的总和)大于 20%。因此,当 GC 时间较长时,将触发此规范。默认情况下,“collect”在“循环缓冲区模式”下运行,默认大小为 500MB。因此,上面的命令将只收集 500MB 的数据(通常是几分钟的数据),然后开始丢弃最旧的数据。当性能计数器触发时,命令将停止,您将拥有导致“性能不佳”的最后几分钟数据(在本例中为 GC 时间过长)。
某些计数器(如系统全局计数器“Memory:Committed Bytes”)没有实例,因为整个计算机只有一个实例。对于这些,请指定一个空字符串。例如
当整台计算机的提交字节数超过 50GB 时,将停止收集。请注意,计数器仍为 CATEGORY:NAME:INSTANCE,但在本例中,INSTANCE 为空字符串(尾随:)。
当 PerfView 检测到计数器满足条件一定秒数(默认为 3 秒)时,将触发性能计数器。可以使用标志 /MinSecForTrigger:N 进行控制,将阈值设置为 N 秒。
当性能计数器触发时,PerfView 实际上会在停止之前再收集 10 秒的跟踪。这样,您就可以在感兴趣的事件发生之前和之后获得条件。当触发性能计数器时,PerfView 会将名为 StopReason 的事件记录到 ETW 事件流中,以便你可以在查看数据时准确查看发生此事件的时间。
若要查找要在 /StopOnPerfCounter' 限定符中使用的性能计数器的确切名称,可以使用 Windows 中内置的 PerfMon 实用工具。若要启动它,只需在命令行中键入“start PerfMon”。然后单击左侧窗格中的“性能监视器”图标。这带来了右手疼痛中的性能计数器图。您可以单击顶部的 + 图标来添加新的性能计数器。这将打开“添加计数器”对话框,其中填充了性能计数器类别。例如,可以打开“.NET CLR 内存”类别,将看到“所有堆中的 # 字节数”和“GC 中的时间百分比”等计数器。然后选择其中一个计数器将显示具有这些计数器的所有实例(进程)。这三个名称(类别、计数器、实例)是需要为 '/StopOnPerfCounter 限定符指定的值。
在等待很长时间之前,您需要测试 /StopOn* 规范,以查看它是否正确捕获跟踪。如果打开日志(或使用 /MaxCollectSec=XXX 强制其快速停止,然后查看 /LogFile 指定的文件,或在“*.etl.zip”的“TraceInfo 视图”中查找此捕获的日志文件),则在监视性能计数器时会找到诊断消息。您应该会看到显示它设置性能计数器的消息以及它每隔几秒钟看到的值。这可以让您确信您没有拼错计数器,您拥有正确的实例,并且您选择了合理的阈值。
可以多次指定 /StopOnPerfCounter 限定符,每个限定符都充当触发器。因此,您将获得所有触发器的逻辑“OR”(其中任何一个都会导致跟踪停止)。目前无法指定逻辑“AND”。
如果要监视的进程存在很长时间,则可以在 /StopOnPerfCounter 限定符中指定该进程的实例。但是,有时很难确定所需的流程实例。某些计数器(如 GC 计数器和其他计数器)具有以某种方式表示“所有”进程的特殊实例。在 PerfMon 的“实例”列表框中查找这些实例。这些可以派上用场。如果没有聚合实例,则可以对可能存在的每个进程实例进行 /StopOnPerfCounter。这并不难做到,因为性能计数器的名称包括 EXE、EXE#1、EXE#2 等。因此,可以为 N 中的每一个指定 /StopOnPerfCounter,从 1 到预期的最大实例数。PerfView 对不存在的实例很可靠 (它等待它们存在) ,因此你可以获得所需的行为。
下面是一些其他有用的 /StopOnPerfCounter 示例
将性能计数器数据记录到 ETL 文件通常很有用,以便可以将性能计数器中的数据与其他 ETW 数据相关联。这就是 /MonitorPerfCounter=spec 限定符的作用。它的格式为 CATEGORY:COUNTERNAME:INSTANCE@NUM其中 CATEGORY:COUNTERNAME:INSTANCE,标识性能计数器(与 PerfMon 相同),NUM 是表示秒的数字。@NUM部分是可选的,默认为 2。在收集数据时,可以有几个这样的限定符。性能计数器的值将作为每 NUM 秒的事件记录到 ETL 文件中。因此
此命令每 10 秒记录一次 Available MBytes 性能计数器。此数据显示在 PerfView/PerformanceCounterUpdate 事件下的“事件”视图中。监视服务器的 RPS 负载或内存使用情况通常很有用。
一个相当常见的情况是,你有一个 Web 服务,并且你有兴趣调查响应时间较长的情况。但是,大多数时候响应时间都很好。因此,简单地收集样本不太可能有用。您需要的是作为“飞行记录器”运行,直到发生长时间的请求,然后停止。这就是 /StopOnRequestOverMSec 限定符的作用。命令
当 IIS(例如 ASP.NET)请求花费的时间超过 2000 毫秒时将停止。还可以添加 /CollectMultiple:N 选项,以便收集其中的 N(文件名经过变形以添加 .1、.2 ....)。
最后,还可以使 PerfView 在将消息写入 Windows 应用程序事件日志时停止。因此,命令:
当消息写入与 .NET 正则表达式模式“Pattern”匹配的 Windows 事件日志时,将停止。默认情况下,PerfView 监视应用程序事件日志,但如果要监视另一个事件日志,可以通过在“Pattern”前面加上事件日志的名称后跟 @ 来实现。
另一个相当常见的情况是,你有一些非基于 HTTP 的服务正在经历暂停时间,并且你有一个大型 .NET 堆。 使用 /gccollectOnly 选项进行收集,您可以进行很长的跟踪(数小时到数天),并且确实发现不时发生长 GC,但只是偶尔发生。 这些长 GC 是阻塞的,因此可能是暂停时间过长的原因,您希望获得有关长 GC 的详细信息。 这就是 /StopOnGCOverMSec 限定符的作用。命令
将收集详细信息,这些信息将在任何超过 5 秒的 GC 之前捕获大约 2 分钟的详细信息。 此详细信息包括有关上下文开关(/ThreadTime 限定符)的信息,并将在关闭之前为 3 个单独的长 GC 收集最多三个单独的文件(命名为默认值:PerfViewData.etl.zip、PerfViewData.1.etl.zip 和 PerfViewData.2.etl.zip)。
另一种常见情况是在引发异常后触发停止。这使您可以查看异常发生之前发生的情况。还可以匹配名称异常或引发的异常中的文本。例如
每当从 MyService 进程中引发具有“ApplicationException”的异常时,将停止(请注意,/Process 会选择具有给定名称的第一个进程作为焦点,而不是具有该名称的所有进程)。/StopOnException 的模式参数可以是任何 .NET 正则表达式。
每当类型中包含“FileNotFound”且消息文本中某处包含“Foo.dll”的异常时,将停止。请注意,您可以在模式中使用 .NET 正则表达式 .*。您可以使用 .Net 正则表达式的全部功能。
默认情况下,当给出任何 /Stop* 参数时,PerfView 将在触发器触发后停止并退出。在一次会话中收集问题的多个实例通常很有用,这就是 /CollectMuliple:N 限定符的作用。例如
只会对超过 5000 个 ASP.NET 请求触发,但是一旦触发,它将返回并恢复监视,直到创建 3 个此类示例。因此,上述命令最多将生成 3 个文件。结果 .ETL.ZIP 文件在 前面有一个数字。ETL.ZIP 后缀,使文件名唯一。
默认情况下,当 ANY 进程满足触发器时,将触发 /StopOn*OverMsec 和 /StopOnException。在运行许多服务的服务器上,如果您只对特定进程感兴趣,则可能会导致错误触发器。这就是 /Process:processNameOrID 限定符的用途。例如
仅当 ID 为 3543 的进程的 Web 请求超过 5000 毫秒时才会触发。您也可以为筛选器使用进程名称(不带路径或扩展名的 exe),但此名称仅用于查找具有该名称的第一个进程。因此,如果在启动收集时有多个进程具有该名称,则选取的确切进程实际上是随机的。因此,您需要对现有进程使用数字 ID,除非进程名称在系统上是唯一的。在收集开始后启动的进程可以明确使用该名称。
使用 /StopOn*Over 或 /StopOnPerfCounter 时可能遇到的一个问题是选择一个好的阈值数。 选择过高的数字将意味着触发器永远不会触发。 选择的数字太低会导致它触发无趣的情况。 这就是 /DecayToZeroHours 选项的用途。 基本思想是将触发器设置为一个数字,该数字位于您认为可能的上限范围内。 还可以将 /DecayToZeroHours:XX 设置为“long”值(通常为 24 小时。 通过指定此选项,您已经指示原始触发值应在这段时间内缓慢衰减为零。 因此,命令
将从 5000 毫秒的停止阈值开始,但它的衰减速度使其在 24 小时内达到零。 因此,在 12 小时内,它将达到 2500 毫秒。 因此,在这段时间内,触发器最终会变得足够小,可以触发,但很有可能它会在“相当大”的情况下触发。
将收集详细信息,这些信息将在任何超过 5 秒的 GC 之前捕获大约 2 分钟的详细信息。 此详细信息包括有关上下文开关(/ThreadTime 限定符)的信息,并将在关闭之前为 3 个单独的长 GC 收集最多三个单独的文件(命名为默认值:PerfViewData.etl.zip、PerfViewData.1.etl.zip 和 PerfViewData.2.etl.zip)。
当 /StopOn* 触发器选项处于活动状态时,PerfView 将以 10 秒为间隔将日志记录到 PerfView 日志以及有关平均请求和最大请求的 ETL 文件消息中。 在进行数据收集时,您可以通过单击主窗口上的“日志”按钮来查看这些日志(即使收集对话框已打开)。 它们也将位于 ETL 文件中,可以通过筛选到“PerfView/PerfViewLog”事件在“事件”视图中查看。 这些有助于更多地了解最大值如何随时间变化。
触发 /StopOn* 触发器后,默认情况下,PerfView 会等待 5 秒,然后停止跟踪。这可确保您不仅看到触发器之前的时间段,还看到触发器之后的 5 秒。这对于大多数方案来说已经足够了,但如果需要更多,可以使用 /DelayAfterTriggerSec=N 指定更长的时间段。但请记住,通常默认的 500Meg 循环缓冲区将仅保存 2-3 分钟的跟踪,因此指定大于 100-200 秒的数字可能会允许触发前的时间段被新数据覆盖。
在某些情况下,还会收集其他日志记录以及 PerfView 数据。当 PerfView 触发停止时,执行停止此日志记录的命令很有用。这就是 /StopCommand 的用途。该参数可以使用变量名称 %OUTPUTDIR% 或 %OUTPUTBASENAME% 来表示目录和要传递给外部命令的基名称(不带目录或文件扩展名的文件名)。
/StopOnRequestOverMSec 用于测量 IIS 启动和 IIS 停止事件之间的持续时间。许多服务使用 IIS 来路由其请求,因此此选项在很多时候都很有用。但是,也可以使用 /StopOnEtwEvent 对发生的单个 ETW 事件或持续时间长于触发量的启动-停止对触发停止。一般语法是
“提供者”的位置
通常,PerfView 的“事件”视图中显示的事件名称是正确的。最后,键值对给出了影响语义的其他“选项”。它们都是可选的,以下是对键值对有效的键。
正如你所看到的,有很多选择,但大多数情况下你不需要它们。此选项对于您自己的 EventSource 事件可能最有用。如果您定义了一个事件“MyWarning”,则可以通过执行以下操作在该警告条件下停止
如果定义了提供程序“MyEventSource”,并且有两个事件“MyRequestStart”和“MyRequestStop”,则只要请求花费的时间超过 2 秒,就可以停止
如果要在名为“GCTest”的进程(即 exe 名为 GCTest.exe)停止时停止(也可以使用进程号)。
如果要在进程启动时停止,则问题会更大一些,因为“start”事件实际上发生在生成进程的进程中,而不是正在创建的进程中。相反,您可以使用 ProcessStart 具有“ImageName”字段这一事实,并且可以使用 FieldFilter 选项的 ~ 运算符来触发该字段。因此,要在启动名为 GCTest.exe 的进程时停止,您可以执行以下操作
下面是一个稍微复杂的示例,我们仅在 GCTest.exe 可执行文件失败并出现非零退出代码时停止。在这里,我们使用 ImageName 字段来查找特定的 Exe,并使用 ExitCode 字段来确定进程是否失败。当大型脚本中的特定进程失败时,可以使用此功能停止 PerfView(这是一种相当常见的情况)。
下面是一个示例,当 ASP.NET 服务器为特定 URL 提供服务时,我们希望停止。基本上,当 ASP.NET Request 事件触发时,我们会停止,并带有与模式匹配的“FullUrl”字段(以 /stop.aspx 结尾)。
下面是一个示例,当磁盘 I/O 花费的时间超过 10000 毫秒时,我们希望停止。我们想要监视 Windows 内核跟踪/DiskIO/读取事件,并在 FieldFilter 表达式中使用“DiskServiceTimeMSec”字段。
通常,该选项非常强大,特别是如果能够将 ETW 事件添加到代码 (EventSource) 与 FieldFilter 结合使用,可以使用它来停止特定进程中的特定 DLL,加载或卸载注册表项、正在触摸的文件、正在打开的文件,以及发生的任何特定 EventSource 事件(测试其参数)。
在前面的示例中,我们打开了与特定提供商关联的所有“关键字”。例如,为了跟踪进程的启动和停止,我们打开了 Microsoft-Windows-Kernel-Process 提供程序中的所有事件。虽然这可行,但这可能意味着触发逻辑必须查看并丢弃许多不重要的事件。通过使用“关键字”选项减少订阅的事件数量,可以提高效率,并使触发的任何调试更容易。例如
这与前面的示例相同,但它具有 Keywords=0x10 选项。这会告知 PerfView 仅打开由 0x10 位字段指定的特定事件。唯一的问题是你怎么知道0x10是什么意思?可以通过查看 Microsoft-Windows-Kernel-Process 提供程序的清单来确定这一点。为此,您可以打开“集合”对话框的高级部分,然后单击“提供程序浏览器”按钮。在“提供商”列表框中选择感兴趣的提供商,然后单击“查看清单”按钮。这将显示提供程序的完整 XML 清单。您将找到一个“关键字”部分,并在其中找到每个关键字的定义。因此,我们发现 WINEVENT_KEYWORD_PROCESS 关键字的值为 0x10,我们可以看到感兴趣的事件 (ProcessStop/Stop) 与该关键字相关联,我们知道这是我们实际需要的唯一关键字。因此,我们知道要给上面的“关键字”选项的“神奇”数字。查找关键字的另一种方法是使用“logman query providers provider”。请注意,您不必这样做,但它确实使调试更容易,处理更高效(因为必须筛选掉的事件更少)。
尝试 /StopOnEtwEvent 限定符并发现它不执行所需的操作(通常是因为它未触发)的情况并不少见。有时,日志中的内容会有所帮助,但 PerfView 不能在日志中放置太多内容,因为它可能会淹没日志。相反,它会将特殊的 PerfView StopTriggerDebugMessage 事件发送到 ETW 流中,以便你可以在“事件”视图中查看数据,并找出它无法正常工作的原因。如果您在触发方面遇到问题,您肯定要查看这些事件。
在许多情况下,只需使用 /StopOnPerfCounter 就足够了(可能还有 /DelayAfterTriggerSec)在有趣的时间点(当性能计数器异常高或低时)收集数据。但是,该技术的缺点是要求收集持续打开。如果兴趣点在性能计数器触发之后很久,则效率低下。在这种情况下,在有趣的时间之前不开始收集事件更有意义。这就是 /StartOnPerfCounter 选项的用途。它的语法与 /StopOnPerfCounter 相同,只是在触发器跳闸之前,它甚至不会开始收集。标志 /MinSecForTrigger:N 适用于 /StartOnPerfCounter,以控制性能计数器在触发收集之前必须满足条件的秒数(默认值为 3 秒)。
.NET V4.5 运行时附带一个名为 System.Diagnostics.Tracing.EventSource 的类,该类可用于以非常方便的方式记录 ETW 事件。例如,这里有一个名为 MyCompanyEventSource 的简单 EventSource,它有一个“Load”和“Unload”事件。每个事件都会记录对该事件有意义的任何有趣信息,在本例中为加载的“imageBase”以及名称。
密封类 MyCompanyEventSource:EventSource { public static MyCompanyEventSource 日志 = new MyCompanyEventSource(); 日志本身 public void Load(long ImageBase, string Name) { WriteEvent(1, ImageBase, Name); public void Unload(long ImageBase) { WriteEvent(2, ImageBase); } 在其他代码中 MyCompanyEventSource.Log.Load(myImageBase, “我的姓名”); 在另一个地方 MyCompanyEventSource.Log.Unload(我的图像库);
由于 EventSources 可以以标准方式记录到 ETW 日志记录文件,因此 PerfView 可以以有用的方式显示这些内容。本节介绍一些常用技术
与所有 ETW 提供程序一样,EventSource 具有唯一标识它的 8 字节 GUID。通常,GUID 使用起来不方便,您更愿意使用名称。如果 ETW 提供程序将自身注册到操作系统,则 PerfView 可以要求 OS 查找名称并获取 GUID。但是,通常 EventSources 不会执行此操作,因为它会使应用程序的部署复杂化。相反,EventSources 通常使用 Internet 标准方式从名称生成 GUID。因此,给定一个名称,您可以找到 GUID,而无需 EventSource 注册自身。PerfView 支持将此约定与 *NAME 语法一起使用。如果提供程序名称以 * 开头,则假定它是提供程序 GUID,该 GUID 是通过以标准方式对 NAME 进行哈希处理而生成的。(哈希不区分大小写)。EventSource 名称是由应用于 EventSource 类的 EventSourceAttribute 的 Name 参数提供的名称,或者是类的简单名称(无命名空间)(如果没有显式给出的名称)。知道 EventSource 的名称后,可以使用 /providers 限定符打开 EventSource。例如
将在详细级别打开名为“MyCompanyEventSource”的所有关键字 (eventGroups) EventSource。请注意,所有这些都只是“标准”ETW。唯一的特殊部分是 *,用于在不注册的情况下引用 EventSource。
在前面的示例中,除了标准内核和 CLR 提供程序之外,还激活了 MyCompanyEventSource。这对于监视细粒度性能非常有用,但对于简单监视来说太冗长了。虽然可以使用 /kernelEvents=none /clrEvents=none /NoRundown 限定符来关闭默认日志记录,但有一个“/onlyProviders”限定符可以使此操作更加容易。因此
将仅从提到的提供程序(在本例中为 MyCompanyEventSource)收集,并关闭所有其他默认日志记录。因此,这些文件往往保持非常小,并且适用于只希望查看 EventSource 消息的情况。
可以通过打开“高级”下拉列表,取消选中“.NET Rundown”、“Kernel Base”和“,在 GUI 中实现与 /OnlyProviders 限定符相同的效果。NET“复选框,然后在”其他提供程序“文本框中添加 EventSource 规范。
就像任何其他 ETW 源一样,可以通过将事件的“关键字”(组)或日志记录的详细程度指定为 /OnlyProviders 限定符 有关此语法的更多详细信息,请参阅 AdditionalProviders 上的帮助。此处一个非常有趣的选项是打开提供程序的“堆栈”选项,该选项将在每次触发 ETW 事件时记录堆栈跟踪。然后,可以在生成的日志文件的“任何堆栈”视图中查看此内容。
收集数据后,可以使用 PerfView 以正常方式查看数据 这几乎肯定意味着打开“事件”视图,选择感兴趣的事件并更新显示。如果需要,可以使用事件视图中的右键单击上下文菜单将事件另存为 XML 或 CSV 文件。
在事件查看器中查看 EventSource 的输出非常适合临时调查,因为 GUI 允许快速筛选和转换为 CSV 或 XML 文件(在 EventViewer 中单击鼠标右键)。 但是,你可能只想使用其他工具分析数据,而这些工具希望与 PerfView/ETW 保持非常松散的耦合。 对于这些应用程序,您只需要获取 ETL 文件并将其转换为 XML 文件,然后可以使用其他工具对其进行处理。 有一个 PerfView 命令可以执行此操作。
上面的命令运行名为“DumpEventsAsXml”的“UserCommand”,为其提供参数“PerfViewData.etl.zip”。 这将创建一个名为 PerfViewData.etl.xml 的文件,该文件是原始文件中所有 ETL 数据的 XML 转储(因此文件可能会变大)。 它适用于任何 ETL 或 ETL.ZIP 文件,但它适用于使用 /OnlyProviders 限定符生成的文件,这些文件仅打开了 EventSources,因此将产生相对较少的输出。
细心的用户会想知道什么是“UserCommand”。PerfView 具有“内置”命令,但它也能够使用用户提供的代码进行扩展(有关详细信息,请参阅 PerfView 扩展)。其中一些用户命令变得足够有用,默认情况下,它们随 PerfView 本身一起提供。DumpEventsAsXml 是这些命令之一。可以通过查看“帮助”->“用户命令帮助”菜单选项来查看 PerfView 当前知道的所有用户命令。
PerfView具有使用命令行命令收集数据的能力,可用于自动执行简单的收集任务,但是对于自动执行分析和收集也很有用。对于这个简单的命令行选项是不够的,您需要编程语言的全部功能来支持各种有用的数据操作。这就是 PerfView 扩展的用途。PerfView 允许创建扩展,该扩展是一个 .NET DLL,它与定义用户定义命令的 PerfView.exe 一起存在。这些命令可以控制 PerfView 的收集或分析功能。它非常强大,开辟了广泛的自动化场景,包括
除了内置的命令行命令(如“run”、“collect”和“view”)外,还有一个“userCommand”。用户命令是在 PerfView 中激活用户定义功能的一种方法。例如,当您运行命令
PerfView 将在 PerfView.exe 旁边查找名为“PerfViewExtensions\Global.dll”的 DLL。然后,它将查找一个名为“Commands”的类型并创建它的实例。然后,它会在该类型中查找名为“DemoCommandWithDefaults”的方法。然后,它将命令的其余参数传递给该方法。通常,方法目标是 varags(它的最后一个参数是 'params string[]'),它允许它处理任意数量的参数。
名为“Global”的扩展名的特殊之处在于,如果用户命令中没有“.”,则该扩展名被假定为“Global”扩展名。因此,上面的命令可以短接到
您还可以使用主查看器上的“文件”->“用户命令”菜单选项 (Alt-U) 从 GUI 调用用户命令。此命令将打开一个对话框,您可以在其中输入命令。PerfView 会记住以前执行的用户命令(甚至在程序调用之间),因此通常只需键入前几个字符就足以选择过去执行过的命令。按 Tab 键将提交完成,按 Enter 键将运行该命令。因此,只需敲几下键盘,您就可以执行用户定义的命令。
帮助>“用户定义的命令”菜单项以及用户命令对话框中的“命令帮助”按钮将打开一个对话框,其中包含有关各种用户定义命令的帮助
在调用用户定义的命令之前,需要创建包含命令的扩展 DLL。这就是 PerfView CreateExtensionProject 命令的作用。由于扩展 DLL 是通过查找相对于 PerfView.exe 的 RELATIVE 来定位的,因此创建自己的扩展的第一步是将 PerfView.exe 复制到你控制的位置。例如:
完成此操作后,您可以执行命令(请注意,我们启动了 perfview 的 LOCAL 副本)
您将在 PerfView.exe 旁边创建 PerfViewExtensions 目录,并执行三项操作
因此,在运行 CreateExtensionProject 命令后,只需打开 PerfViewExtenions\Extensions.sln 即可运行、编译和测试新的 PerfView 扩展。如果您安装了 VS2010,则可以在几秒钟内启动并运行。
因此,最好的开始方法可能是:
熟悉 PerfView 对象模型后,需要意识到一个重要的注意事项
这意味着,如果要将 PerfView.exe 升级到较新版本,则很有可能必须更新扩展以匹配自上一版本以来对 PerfView 所做的任何更改。原因很简单。PerfView 对象模型实际上最好被认为是“Beta”版本,因为根本没有足够的时间来找到最佳的 API 图面。因此,变化是不可避免的,保持兼容性的成本根本不值得。因此,您可以自由创建 PerfView 扩展,但在决定创建扩展时,必须准备好支付升级的移植成本。
用户命令使您能够调用代码来创建专用的数据视图,但它并未集成到 GUI 本身中。本部分介绍如何使用户命令成为正常 GUI 体验的一部分。执行此操作的关键是 PerfView.exe 文件旁边的“PerfViewExtensions”目录中的“PerfViewStartup”文件。如果存在此类文件,则此文件中的命令将在 PerfView 启动时执行。此文件是逐行读取的,并具有以下命令
Linux 有一个称为 Perf Events 的内核级事件日志记录系统,它与 ETW 没有什么不同,特别是知道如何以定期间隔(例如 1 毫秒)捕获 CPU 堆栈 PerfView 知道如何读取此数据,因此可以使用 Linux 上的 Perf 事件工具收集数据,将数据复制到 Windows 计算机,并使用 PerfView 的堆栈查看器进行查看。本节的其余部分大部分内容都是 linux-performance-tracing.md 文档的克隆。您可能还希望在那里查看是否有这些说明的最新版本。
Brian Robbins编写了一个BASH(shell)脚本,该脚本将运行Perf.exe,解析符号,并将所有信息收集到ZIP文件中,以便传输到另一台计算机。您可以使用网络浏览器或使用“cURL”实用程序下载它
下载后,要让它运行,您必须使其可执行
如果这可行,你应该能够做到
它应该打印出一些帮助。
您将需要 Perf.exe 命令以及 LTTng 包,您可以通过执行以下操作来获取这些命令
请注意,您需要成为超级用户才能执行此操作,因此如果您还没有成为超级用户,这就是为什么上面的命令在执行安装脚本之前使用 sudo 命令提升为超级用户的原因。
如果运行的是 .NET 运行时应用程序,则必须设置一个环境变量,该变量将告知运行时发出有关实时 (JIT) 编译方法的符号信息。因此,在运行应用程序之前,必须确保设置了以下环境变量
此时,您可以开始收集。为此,请打开另一个命令窗口并运行以下命令。
此时,您可以转到第一个窗口(设置COMPlus_PerfMapEnabled)并启动应用程序。应用程序完成后,可以使用 Ctrl-C 停止收集。结果是 FILENAME.trace.zip 文件。这包含跟踪以及用于解析符号信息的所有其他文件。
创建 FILENAME.trace.zip 文件后,可以将其传输到 Windows 计算机,只需使用 PerfView 打开它即可。它将在 CPU 示例的堆栈窗口中打开文件,并且 CPU 调查的所有常规技术都适用。
引擎盖下发生的事情是 PerfView 正在打开 FILENAME.trace.zip 文件以在存档中找到后缀为 *.data.txt 的文件并读取该文件。此文件应为运行“Perf script”命令的输出。PerfView 还知道如何直接读取带有 *.data.txt 后缀的文件,因此,如果您不希望在收集 Linux 数据时使用“perfcollect”脚本,您仍然可以轻松地将数据提供给 PerfView。(还可以将 *.data.txt 文件压缩成后缀为 *.trace.zip 的文件,PerfView 会很乐意打开它)
PerfView 最强大的方面之一是其堆栈查看器。也许这个查看器最有趣的事情之一是它非常通用。此查看器中显示的数据只是一组示例,其中每个示例包含
堆栈查看器的所有其他魔力、包容性和排他性成本、时间线、过滤、调用方和被调用方视图,都只是这些数据的不同聚合。
这意味着几乎任何分层数据都可以在堆栈查看器中有用地显示。例如,磁盘视图上的大小只是将文件名的路径作为形成“堆栈”的路径,并将文件的大小作为指标来形成磁盘视图上总大小的模型。这意味着可以使用堆栈查看器查看来自其他探查器或数据形成层次结构的任何其他地方的数据。
现在,在 PerfView 的实现中,有一个名为“StackSource”的类,它表示此示例列表,其中包含 PerfView 的查看器查看的堆栈。还有一个名为“InternStackSource”的类,旨在使读取其他格式变得容易,并将该数据转换为StackSource。但是,PerfView 还具有两种格式,可以非常轻松地允许其他工具输出 perfview 可以简单读取的堆栈。其中一种格式是基于XML的,另一种是基于JSON的,它们都不足为奇,它们只是堆栈查看器在这些格式中需要的数据的“明显”编码。例如,下面是 .perfView.xml 格式的示例
<采样时间=“10” 指标=“10”> Helper嵌套 助手1 功能3 功能 主要 <采样时间=“20” 指标=“10”> 功能3 功能 主要 <采样时间=“30” 公制=“10”> 助手X 助手1 功能3 功能 主要 <采样时间=“40” 公制=“10”> 功能 主要
您可以看到格式可以非常简单。有一个“StackSource”元素,它有一个成员“Samples”,而“Samples”又包含一个 Sample 列表,每个 Samples 都有一个时间和一个指标(这两者都是可选的,时间默认为 0,指标默认为 1) 每个示例中都有一个堆栈帧列表,每行一个。它们按从最具体(或最深的调用树嵌套)到最不具体(主程序)的顺序排列。这就是 PerfView 读取数据所需的全部内容。只需将上述文本粘贴到“*.perfView.xml”文件中,然后在 perfview 中打开该文件即可尝试此操作。PerfView 将在堆栈查看器中打开该数据(尝试一下!
有相应的 *.perfView.json 格式,该格式与 XML 格式完全类似。基本结构是相同的:StackSource 具有相同的示例列表,每个示例具有表示堆栈的时间、指标和名称列表。下面是一个示例。与前面的示例一样,可以剪切并粘贴到 *.perfView.json 文件中,然后在 PerfView 中打开它,以在堆栈查看器中查看数据。
{ “堆栈源”:{ “样本” : [ { “时间” : “10”, “公制”: “10”, “堆栈”:[ “HelperNested”, “助手 1”, “功能”, “主要” ] }, { “时间” : “20”, “公制”: “10”, “堆栈”:[ “Func3”, “功能”, “主要” ] }, { “时间” : “30”, “公制”: “10”, “堆栈”:[ “助手X”, “助手 1”, “Func3”, “功能”, “主要” ] }, { “时间” : “40”, “公制”: “10”, “堆栈”:[ “功能”, “主要” ] } ] } }
简单的格式很好,因为它很容易解释,但效率非常低。您可以看到,对于每个样本,每个堆栈都必须完整地重复,并且大多数情况下,堆栈彼此非常相似。此外,当你将示例读入查看器时,你不会获得 PerfView 的分组、折叠和筛选选项的任何默认值,这使得体验不太理想。
好吧,.perfView.xml 格式实际上比到目前为止显示的要复杂得多。事实上,您可以将 ID 分配给堆栈的每个唯一帧,并使用 ID 而不是名称(节省大量空间)。同样,您可以将 ID 分配给可在示例中使用的每个唯一堆栈(从帧 ID 构建)(节省更多空间)。这种压缩大大缩短了加载数据的时间。最后,可以为每个堆栈查看器文本框指定所有默认值和所有选项(例如,Group Pats、Fold Pats Include Pats ...文本框)。简而言之,在生成 .perfView.xml 文件时,只需多做一点工作,就可以使体验明显更好。
与其记录这些格式的具体格式,不如简单地向您展示一个示例。PerfView 堆栈查看器具有“文件->保存”命令,这会将当前堆栈视图另存为 .perfView.xml.zip 文件。如果解压缩此文件,则将看到数据数据以这种更完整、更高效的格式表示。因此,您可以采用上面的示例之一,打开它,将一些数据添加到文本框(记住历史记录)中,然后保存视图。然后你解压缩它并查看格式。格式完全简单明了。
Windows 性能分析器 (WPA) 是由 Windows 构建的工具,作为 Windows 评估和部署工具包的一部分免费提供。与 Windows 性能记录器 (WPR) 一起,它可用于收集和查看 ETW 数据。由于它们都使用相同的数据格式(ETW 跟踪日志 (ETL) 文件),因此使用一种工具进行收集并使用另一种工具进行查看很容易。这很有用,因为 WPA 具有 PerfView 所没有的非常强大的绘制和查看数据的方法,并且 PerfView 具有收集 WPA 中不存在的数据和其他视图的强大方法。
PerfView 具有许多生产监视(例如 /StopOnPerfCounter)功能,而这些功能目前 WPR 没有。此外,PerfView 易于从任何 Web 下载,并且 XCOPY 部署为单个 EXE,这使得 PerfView 非常适合在现场收集数据。在这种情况下,只需使用 PerfView collect 命令(如果可能正在执行挂钟调查,则使用 /threadTime 选项)进行收集,结果将是 .ETL.ZIP 文件已准备好上传。遗憾的是,目前WPA不会打开ETL.ZIP文件,但您可以使用以下命令
这将解压缩数据文件以及任何 NGEN PDBS 并将它们存储在 .NGENPDB 文件夹,因此以这种方式解压后,可以在数据文件上运行 WPA 命令来查看 WPA 中的数据。
在上面的方案中,PerfView 将像往常一样设置 ETW 提供程序。但是,PerfView 还能够模拟 WPR 默认打开的提供程序。因此,如果您希望使用 PerfView 收集数据并尝试尽可能多地模拟 WPR,请使用以下命令收集数据。
这应该会生成与 WPR 生成的数据文件非常接近(如果不完全相同)的数据文件。具体而言,它不会生成 ZIPPed 文件,而是输出 .ETL 文件和 .NGENPDB 目录,就像 WPR 一样。与所有集合命令一样,可以使用“/Providers”限定符添加更多提供程序,也可以使用 /KernelEvents 或 /ClrEvents 限定符来微调 Kernel 和 .NET 提供程序事件。
如果希望像 WPR 一样生成文件,但利用 PerfView 的 ZIPPing 功能,则可以组合 /wpr 和 /zip 命令,如下所示。
此命令将像 WPR 一样打开提供程序,但会像 PerfView 一样对其进行 ZIP。这对于远程收集很有用。您可以使用它来收集数据,并使用 PerfView /wpr unzip 在其目标位置解压缩数据,以便使用 WPA 进行查看。
PerfView 具有许多 WPA 所没有的视图和查看功能。因此,在 PerfView 中查看使用 WPR 收集的数据通常很有用。此方案“有效”:PerfView 已经知道如何打开 ETL 文件,并且它足够聪明,可以注意到符号信息的 NGENPDB 目录并适当地使用它。
大多数与查看无关的功能都可以从命令行获得,以便轻松实现数据收集的自动化。 在命令行键入
或者,从 PerfView 主窗口导航到“帮助->命令行帮助”将提供更完整的详细信息。
有关为 PerfView 生成扩展的信息,另请参阅 PerfView 扩展。
默认情况下,PerfView 在执行任何操作(包括数据收集)时将始终显示一个 GUI 窗口。这样做是为了允许报告错误。对于无人值守的自动化,这可能是不可取的。这是 /LogFile:FileName 限定符的用途。当指定此限定符而不是启动 GUI 时,该命令会将所有输出发送到指定的文件。其目的是脚本将使用此限定符来避免 GUI。如果命令成功,PerfView 的退出代码将为 0。
PerfView 数据收集基于 Windows 事件跟踪 (ETW) 。这是以低开销方式记录信息的通用工具。它在整个 Windows 操作系统中非常有用,特别是 Windows 操作系统内核和 .NET CLR 运行时都使用它。默认情况下,PerfView 会选择一组默认的事件,这些事件对 PerfView 可以可视化的分析类型具有较高的价值。但是,PerfView 也可以简单地用作数据收集器,此时打开其他事件可能很有用。这就是 /KernelEvents: /ClrEvents: 和 /Provider: 限定符的作用
所有 ETW 事件都记录以下信息
到目前为止,Windows 内核中内置的 ETW 事件是最基本和最有用的事件。几乎任何数据收集都希望至少打开其中的一些。PerfView 将内核事件分为三组 请参阅内核 ETW 事件
默认组是 PerfView 默认打开的组。 这些事件中最详细的是“配置文件”事件,该事件每毫秒触发一次计算机上每个 CPU 的堆栈跟踪(以便您知道 CPU 在做什么)。 因此,在 4 处理器机器上,每秒跟踪时间将获得 4000 个样本(带有堆栈跟踪)。 这可以加起来。 假设每秒跟踪将获得至少 1 Meg 的文件大小。 如果需要运行很长的跟踪(100 秒),则应强烈考虑使用循环缓冲区模式来控制日志。 以下是您在默认组下获得的事件:
默认情况下,以下内核事件不处于打开状态,因为它们可能相对详细,或者用于更专业的性能调查。
最后一组内核事件通常对于编写设备驱动程序或试图理解硬件或低级操作系统软件行为异常的原因的人很有用
除了内核事件之外,如果运行的是 .NET 运行时代码,则可能还需要打开 CLR ETW 事件。默认情况下,PerfView 会打开其中的一些功能。有关这些事件的详细信息,请参阅 CLR ETW 事件。
ASP.NET 有一组事件,这些事件在处理每个请求时发送。 PerfView 具有一个特殊视图,可以在打开 ASP.NET 事件时打开该视图。 默认情况下,PerfView 会打开 ASP.NET 事件,但是,在安装 ASP.NET 时,还必须选择“跟踪”选项才能使这些事件正常工作。 因此,如果您没有看到 ASP.NET 事件,则您正在运行 ASP.NET 方案,这可能是您未获取数据的原因之一。
启用 ASP.NET 跟踪
打开跟踪的最简单方法是使用操作系统附带的 DISM 工具。 从提升的命令提示符运行以下命令
请注意,此命令将重新启动 Web 服务(使其生效),如果 ASP.NET 服务处理较长(许多秒)的请求,这可能会导致复杂情况。这将强制 DISM 延迟(重新启动)或中止未完成的请求。因此,您可能希望将其安排在其他服务器维护中。在特定计算机上完成此配置后,它将持续存在。
您也可以使用 GUI 界面手动完成此配置。 您首先需要进入用于配置 Windows 软件的对话框。 这取决于您使用的是客户端还是服务器版本的操作系统。
另请参阅源代码查找。
在收集时,当获取 CPU 样本或堆栈跟踪时,它由内存中的地址表示。 此内存地址需要转换为符号形式才能用于分析。 这分两步进行。
如果第一步失败(不常见),则为地址提供符号名称?!?(未知的模块和方法)。但是,如果第二步失败(更常见),那么您至少可以知道模块,并且地址被赋予符号名称模块?.
不属于任何 DLL 的代码必须是动态生成的。如果此代码是由 .NET 运行时通过编译 .NET 方法生成的,则它应该已由 PerfView 解码。但是,如果指定了 /NoRundown 或日志文件不完整,则解码地址所需的信息可能已丢失。然而,更常见的是,运行时会生成许多“匿名”帮助程序方法,并且由于这些方法没有名称,因此除了将它们保留为?!?.之外,没有太多事情可做这些帮助程序通常不感兴趣(它们没有太多独占时间),并且可以在分析期间折叠到其调用程序中(将?!?添加到 FoldPats 文本框)。它们通常发生在托管代码和非托管代码的边界处。
未在运行时生成的代码始终是 DLL 正文的一部分,因此始终可以确定 DLL 名称。预编译的托管代码位于 (NGEN) 映像中,这些映像的名称中包含 .ni,并且信息应位于 PerfView 收集的 ETL 文件中。如果您在包含 .ni 的模块中看到未知的函数名称,则意味着 CLR rundown 出了问题(请参阅 ?!? 方法)。对于非托管代码(没有 .ni),需要在与该 DLL 关联的符号信息中查找地址。此符号信息存储在程序数据库文件 (PDB) 中,并且解析大型跟踪的成本可能相当高(10 秒或更长时间)。因此,默认情况下,PerfView 不会解析任何非托管符号。
相反,它会等到您作为用户请求更多符号信息。通常,这是在堆栈查看器中通过右键单击带有模块的单元来完成的!?名称,然后选择“查找符号”。这表示 PerfView 应搜索 PDB 文件并解析它可以在模块中的任何名称。查找正确 PDB 的问题并不少见,因此不能保证成功,可能需要几秒钟才能完成。如果“查找符号”失败,请参阅日志文件。
通常,PerfView 支持在多个单元上执行命令。 这对于符号解析非常方便。 例如,如果有几个未解析的模块看起来很感兴趣(因为它们的 CPU 使用率很高),您可以将它们全部选中(通过拖动或按住 shift 键单击),然后选择“查找符号”。
可以从命令行“预取”符号。为此,请指定 /SymbolsForDlls:dll1,dll2 ...启动 PerfView 时。传递给 /SymbolsForDlls 的列表中的 dll 没有其文件扩展名或路径。
到目前为止,最常见的非托管 DLL 是 Microsoft 作为操作系统的一部分提供的 DLL。 因此,如果未指定_NT_SYMBOL_PATH则 PerfView 将使用以下“标准”方法
这表示在标准 Microsoft PDB 服务器 https://msdl.microsoft.com/download/symbols 查找 PDB,并将它们本地缓存在 %TEMP%\SymbolCache 中。 因此,默认情况下,您始终可以找到标准 Microsoft DLL 的 PDB。
但是,如果你对Microsoft不发布的 DLL 的符号感兴趣(例如,你自己的非托管代码),则必须在启动 PerfView 之前提供指定查找位置的_NT_SYMBOL_PATH。
如果需要更改符号路径,可以在启动 PerfView 之前设置 _NT_SYMBOL_PATH 环境变量,也可以使用 StackViewer 窗口中的“文件”->“SetSymbolPath”菜单选项。 此命令将弹出一个简单的对话框,显示_NT_SYMBOL_PATH变量的当前值,并允许您更改它。 _NT_SYMBOL_PATH是以分号分隔的查找符号的位置列表。每个此类条目可以是
通常,如果在执行“查找符号”时没有获得非托管符号,请检查日志,并在必要时向符号路径添加新路径。另请参阅符号解析。
PerfView 支持 Azure DevOps 符号服务器,它将使用本地开发凭据(Visual Studio 或 VSCode)或提示你登录来自动进行身份验证。
SRV*localPath*https://yourorg.artifacts.visualstudio.com/_apis/Symbol/symsrv
SRV*localPath*https://artifacts.dev.azure.com/yourorg/_apis/symbol/symsrv
因此,通常您只需要获得好的符号
如果要调查不是来自 Microsoft 的 EXE 的非托管 DLL 的性能问题(例如,你自己生成了它们),则必须在启动 PerfView 之前将_NT_SYMBOL_PATH设置为包含这些 PDB 的位置。
选择具有 !?在查看器中,右键单击并选择“查找符号”
一个非常有用但容易被忽视的功能是 PerfView 的源代码支持。通过在堆栈查看器中选择名称并键入 Alt-D(D 表示定义),或右键单击并选择“转到源”来激活此支持。这将在文本编辑器中显示该名称的源代码,其中每一行都用该行的指标进行了注释。此功能对于在方法中进行分析是必不可少的,并且通常对于理解代码的一般功能也很有用。
源代码支持是一种相对脆弱的机制,因为除了具有以符号方式查找方法名称 (PDB) 的所有信息外,PerfView 还需要行级信息以及对源代码本身的访问。这些额外的条件很容易被破坏,这将破坏该功能。但是,源代码支持通常非常有用,因此值得麻烦地让事情正常工作。
为了使源代码正常工作,您需要满足以下条件
PerfView 在 PerfView 的日志中提供了查找源代码所执行步骤的详细消息。因此,如果在查找源代码时有任何问题,则此日志是开始的地方。
通常不需要设置 _NT_SOURCE_PATH 变量,因为默认情况下,PerfView 将搜索原始生成时位置(如果在运行的同一台计算机上生成,则该位置将起作用)以及 PDB 符号文件中指定的符号服务器(如果代码已使用源服务器编制索引,则该位置有效)。但是,在其他情况下,您必须设置_NT_SOURCE_PATH。就像 _NT_SYMBOL_PATH 的情况一样,您可以通过转到堆栈查看器的 File -> 'Set Source Path' 菜单条目在 GUI 中设置此变量。此值在 PerfView 程序的不同调用中保留。
另请参阅源代码查找。
如果符号位于Azure DevOps项目存储中,或者源代码不是公开的,则 PerfView 可能会提示你登录。目前支持Azure DevOps和专用GitHub存储库。如果已安装,PerfView 将尝试使用 Git 凭据管理器,该管理器通常随 Git For Windows 一起安装。如果未安装 Git 凭据管理器,PerfView 将回退到备用身份验证机制。可以在 PerfView 主窗口的“选项”菜单上的“身份验证”子菜单上配置身份验证机制。身份验证选项如下所述。
获取样本时,ETW 系统会尝试进行堆栈跟踪。 由于各种原因,在采用完整堆栈之前,此操作可能会失败。 PerfView 使用启发式方法,即所有堆栈都应以负责创建线程的特定 OS DLL (ntdll) 中的帧结尾。 如果堆栈未在此处结束,则 PerfView 假定它已损坏,并在线程和提取的堆栈部分之间注入一个名为“BROKEN”的伪节点(至少它将具有获取示例的地址)。 因此,BROKEN 堆栈应始终是表示操作系统线程的某个帧的直接子级。
当 BROKEN 堆栈的数量很少(例如<总样本的 3%)时,可以简单地忽略它们。 这是常见的情况。 然而,破碎的堆栈越多,“自上而下”分析(使用CallTree视图)的用处就越小,因为实际上一些重要的样本部分没有被放置在适当的位置,在堆栈顶部附近给你倾斜的结果。 “自下而上”分析(首先查看样品发生的方法)不受损坏堆栈的影响(但是,当该分析“向上”移动时,它可能会受到影响)
损坏堆栈的发生原因如下
如果您正在分析一个 64 位进程,那么您很有可能受到上述场景 (2) 的影响。 在这种情况下,有三种解决方法可以解决损坏的堆栈
C:\Windows\Microsoft.NET\Framework64\v4.0.30319\N安装 YourApp.exe。
对于服务器应用程序,通常没有可以传递给上述 NGEN 命令的主 EXE,但是您可以使用相同的语法 (NGEN install DLLPATH) 对特定 DLL 进行 NGEN。如果不知道 DLL 的路径名称,可以通过转到“事件”视图并选择“ModuleLoad”和“ModuleDCStop”事件以及“ModuleILPath”和“ModuleNativePath”列来找到它们。任何没有“ModuleNativePath”的 DLL 都是 NGEN 的候选者。
对于 ASP.NET 应用程序,您可以按照此博客中的说明进行设置,以便以 32 位进程加载页面
丢失的堆栈帧与损坏的堆栈不同,因为丢失的是堆栈“中间”的帧。 通常只缺少一种或两种方法。 缺少堆栈有三个基本原因。
虽然丢失的帧可能会造成混淆,从而减慢分析速度,但它们很少真正阻止它。 缺失帧是以非常低的开销方式分析未修改的代码所付出的代价。
以下是一些有用的技术,起初可能并不明显:
PerfView 发出 ?对于它无法解析为符号名称的任何程序地址。有关详细信息,请参阅符号和符号解析疑难解答。
如果在数据采样时获取的堆栈跟踪未在启动线程的 OS DLL 中终止,则堆栈被视为已损坏。有关详细信息,请参阅损坏的堆栈。
用于爬取堆栈的算法并不完美。在某些情况下,堆栈上没有足够的信息来快速找到调用方。此外,编译器还执行内联、尾调用和其他操作,这些操作在运行时完全删除帧。好消息是,虽然有时会令人困惑,但通常很容易填补空白。有关详细信息,请参阅缺失帧。
为了获得 .NET 方法的良好符号信息,CLR 运行时必须将映射从本机指令位置转储到方法名称。这是在进程关闭时完成的 (,或者当 PerfView 请求和显式运行) 时完成的。从分析的角度来看,这所消耗的 CPU 是无趣的(因为它不会正常发生)。排除此时间的最简单方法是设置一个不包括进程关闭的时间范围。有关详细信息,请参阅缩放到感兴趣的范围。
PreStubWorker 是 .NET 运行时中的方法,它是 .NET 运行时实时编译器中的第一个方法。 首次调用方法以将 EXE 中的代码(不是本机代码)转换为可由处理器执行的本机代码时,将调用此方法。 如果此帮助程序(包括)中的时间量很大,则可以通过使用 NGEN.exe 工具预编译代码来减少时间。
首次收集 ETW 数据时,它实际上位于两个文件中。ETL 文件(查看器显示)和 .Kernel.ETL 文件(查看器对您隐藏)。此外,如果您希望在另一台机器上检查数据,这些文件不包含所需的信息(精确的 dll 版本)。合并是合并这些文件并添加额外信息的过程。由于合并可能需要一些时间(10 秒),因此默认情况下不会进行合并,并且查看器会通过显示“(未合并)”来指示这一点。这是对您的警告,如果您希望将此文件复制到另一台计算机,则需要先将其合并。有关详细信息,请参阅合并。
NT 性能团队有一个名为 XPERF 的工具(以及一个名为 Windows Performance Analyzer (WPA) 的较新版本),它对于进行性能分析也非常有用。事实上,PerfView 和 XPERF/WAP 不应真正被视为竞争对手。事实上,它们都使用相同的数据(由各种 ETW 提供程序收集的 ETW 数据)。由XPERF创建的ETL文件可以通过PerfView查看,反之亦然,因为它们确实是非常相似的程序。那么你应该使用哪个呢?好消息是,这并不重要,因为您可以随时改变主意。目前,PerfView 具有更多的电源分组功能,因此 XPERF 用户在遇到“平面”配置文件时可能希望试用 PerfView。相反,WPA 具有更好的图形功能以及 PerfView 所没有的内存视图。
PerfView 具有 /wpr 限定符,可在使用 WPA 查看使用 PerfView 收集的数据时缓解一些摩擦。有关详细信息,请参阅使用 WPA。
Visual Studio 还内置了一个探查器,那么问题来了,为什么不使用它呢? 答案是你应该! 但是,Visual Studio 探查器的目标是在开发时简化分析。 此外,它还专注于 CPU 问题。 如果需要“在现场”收集配置文件信息(通常包括测试实验室),则很难使用 VS 探查器(必须安装它,包括创建设备驱动程序)。 附加到服务也很麻烦(通常存在安全问题)。 结果是,在开发时间之外很难使用 VS 探查器。
{ “堆栈源”:{ “示例”:[ { “时间”: “10.1”, “堆栈”:[ “为示例 1 执行 func”, “呼叫功能”, “主要” ] }, { “时间”: “10.1”, “堆栈”:[ “为示例 2 执行 func”, “呼叫功能”, “主要” ] } ] } }
<采样时间=“10”> 为示例 1 执行 Func 调用 Func 主要 <采样时间=“20”> 为示例 2 执行 Func 调用 Func 主要