内功修炼-网络数据包的发送、传输、接受过程
TCP/IP模型
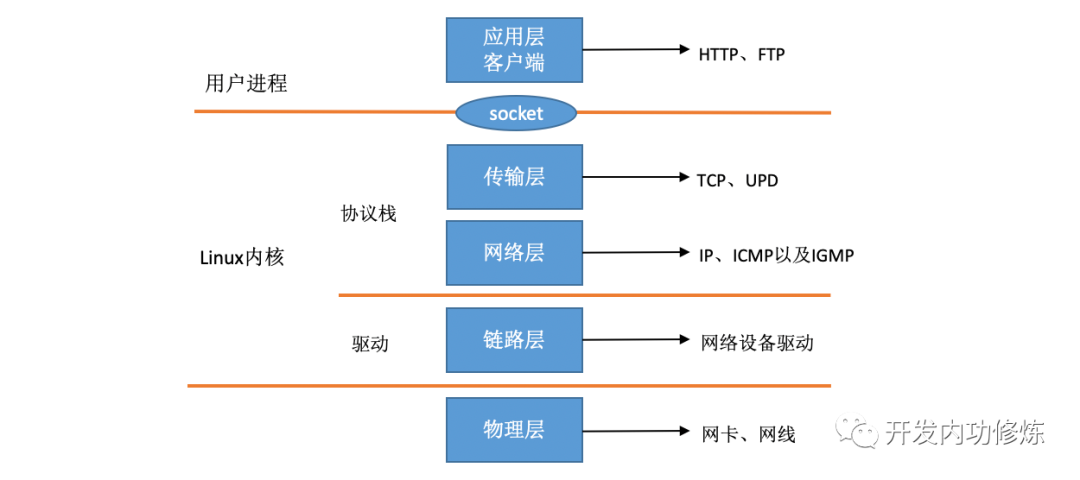
TCP/IP模型是网络编程的基础,在TCP/IP网络分层模型里,整个协议栈被分成了物理层、链路层、网络层,传输层和应用层。物理层对应的是网卡和网线,应用层对应的是我们常见的Nginx,FTP等等各种应用。Linux实现的是链路层、网络层和传输层这三层。
在Linux内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。
网络数据包的发送过程
int main(){
fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, ...);
cfd = accept(fd, ...);
// 接收用户请求
read(cfd, ...);
// 用户请求处理
dosometing();
// 给用户返回结果
send(cfd, buf, sizeof(buf), 0);
}
以上是c语言中网络编程的基础,今天我们讨论调用send之后内核是怎么样把数据包发送出去的,本文基于Linux3.10,网卡驱动采用Intel的igb网卡举例。
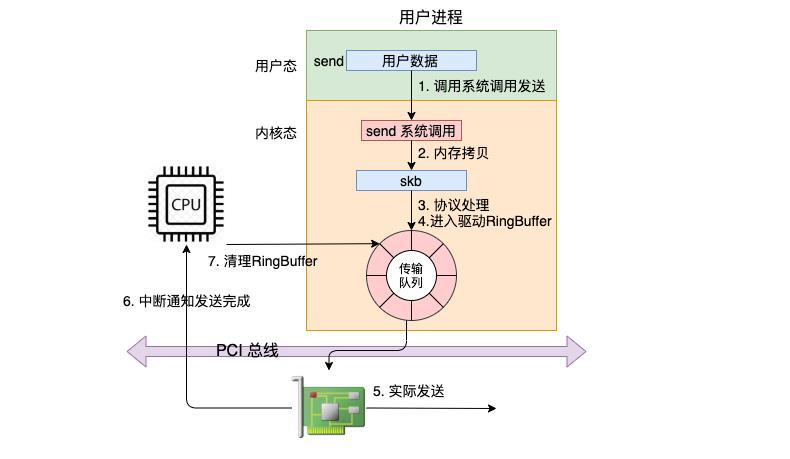
在这幅图中,我们看到用户数据被拷贝到内核态的skb中,然后经过协议栈处理后进入到了RingBuffer中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知CPU,然后清理RingBuffer。
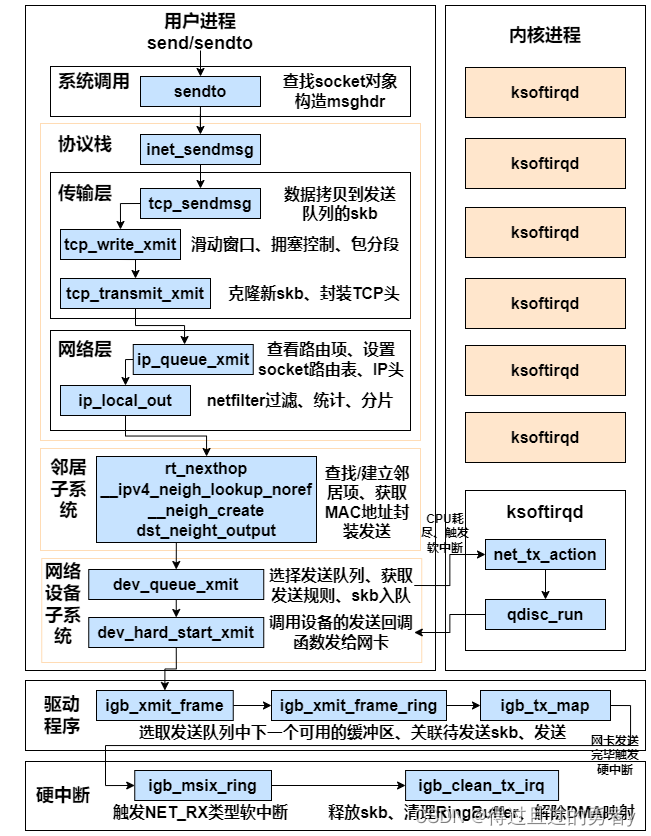
网络包发送过程总览
关键技术点-网卡与RingBuffer(环形缓冲区)
在一个网卡中通常会有多个RingBuffer,网卡在启动时最重要的任务之一就是分配和初始化 RingBuffer,理解了 RingBuffer 将会非常有助于后面我们掌握发送。
实际上一个 RingBuffer 的内部不仅仅是一个环形队列数组,而是有两个。
- igb_tx_buffer 数组:这个数组是内核使用的,通过 vzalloc 申请的。
- e1000_adv_tx_desc 数组:这个数组是网卡硬件使用的,硬件是可以通过 DMA 直接访问这块内存,通过 dma_alloc_coherent 分配。
将来在发送的时候,这两个环形数组中相同位置的指针将都将指向同一个 skb。这样,内核和硬件就能共同访问同样的数据了,内核往 skb 里写数据,网卡硬件负责发送。
关键技术点-struct sk_buff(常简称为skb/sk_buff)
sk_buff(socket buffer)结构是linux网络代码中重要的数据结构,linux网络中的所有数据包的封装以及解封装都是在这个结构体的基础上进行。主要包含两个部分,其一:管理数据,即数据包的管理信息;其二:报文数据,保存了实际网络中传输的数据,在内核协议栈起承上启下的作用
struct sk_buff_head
{
// 双向链表
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
}
struct sk_buff
{
// 双向链表
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sock ; //struct sock是socket在网络层的表示,其中存放了网络层的信息
unsigned int len; //下面有介绍
unsigned int data_len; //下面有介绍
__u16 mac_len ; //数路链路层的头长度
__u16 hdr_len ; //writable header length of cloned skb
unsigned int truesize ; //socket buffer(套接字缓存区的大小)
atomic_t users ; //对当前的struct sk_buff结构体的引用次数;
__u32 priority ; //这个struct sk_buff结构体的优先级
sk_buff_data_t transport_header ; //传输层头部的偏移量
sk_buff_data_t network_header ; //网络层头部的偏移量
sk_buff_data_t mac_header ; //数据链路层头部的偏移量
char *data ; //socket buffer中数据的起始位置;
sk_buff_data_t tail ; //socket buffer中数据的结束位置;
char *head ; //socket buffer缓存区的起始位置;
sk_buffer_data_t end ; //socket buffer缓存区的终止位置;
struct net_device *dev; //将要发送struct sk_buff结构体的网络设备或struct sk_buff的接收
//网络设备
int iif; //网络设备的接口索引号;
struct timeval tstamp ; //用于存放接受的数据包的到达时间;
__u8 local_df : 1 , //allow local fragmentaion;
cloned : 1 , // head may be cloned
;
__u8 pkt_type : 3 , //数据包的类型;
fclone : 2, // struct sk_buff clone status
}
sk_buff组成
- Packet data:通过网卡收发的报文,包括链路层、网络层、传输层的协议头和携带的应用数据,包括head room,data,tail room三部分。
- skb_shared_info 作为packet data的补充,用于存储ip分片,其中sk_buff *frag_list是一系列子skbuff链表,而frag[]是由一组单独的page组成的数据缓冲区。
- Data buffer:用于存储packet data的缓冲区,分为以上两部分。
- Sk_buff:缓冲区控制结构sk_buff。
发送tcp报文示例
发送报文时,在不同协议层处理数据时,该数据要添加相应的协议头。因此,最高层添加数据和自身的协议头。alloc_skb用来申请一个sk_buff。skb_reserve用来创建头空间。skb_put用来创建用户数据空间,用户数据复制到sk->data指向的数据区。接下来使用skb_push是在用户数据的前面加上各层协议头。
- 1)当TCP发送数据时,它根据一些条件分配一个缓冲区(比如,TCP的最大分段长度(mss),是否支持散读散写I/O等
- 2)TCP在缓冲区的头部预留足够的空间(用skb_reserve)用于填充各层的头部(如TCP,IP,链路层等)。MAX_TCP_HEADER参数是各层头部长度的总和,它考虑了最坏的情况:由于tcp层不知道将要用哪个接口发送包,它为每一层预留了最大的头部长度。它甚至考虑了出现多个IP头的可能性(如果内核编译支持IP over IP,我们就会遇到多个IP头的情况)。
- 3)把TCP的负载拷贝到缓冲区(用skb_put,复制数据)。需要注意的是:图7只是一个例子。TCP的负载可能会被组织成其他形式。例如它可以存储到分片中。
- 4)TCP层添加自己的头部(用skb_push)。
- 5)TCP层把缓冲区传递给IP层,IP层同样添加自己的头部(用skb_push)。
- 6)IP层把缓冲区传递给邻居层,邻居层添加链路层头部(用skb_push)。
send调用系统sendto实现
我们在用户态使用的send函数和sendto函数其实都是sendto系统调用实现的。send只是为了方便,封装出来的一个更易于调用的方式而已。
在sendto系统调用里,首先根据用户传进来的socket句柄号来查找真正的socket内核对象。接着把用户请求的 buff、len、flag 等参数都统统打包到一个 struct msghdr 对象中。
传输层处理
传输层拷贝
在进入到协议栈 inet_sendmsg 以后,内核接着会找到 socket 上的具体协议发送函数。对于 TCP 协议来说,那就是 tcp_sendmsg,在这个函数中,内核会申请一个内核态的skb内存,将用户待发送的数据拷贝进去。注意这个时候不一定会真正开始发送,如果没有达到发送条件的话很可能这次调用直接就返回了。
// 逻辑比较复杂,代码总只显示了skb拷贝的相关部分
// file: net/ipv4/tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size) {
...
//获取用户传递过来的数据和标志
iov = msg->msg_iov; // 存储的是用户态内存的要发送的数据的buffer,后面会拷贝到内核的skb
iovlen = msg->msg_iovlen; //数据块数为1
flags = msg->msg_flags; //各种标志
...
while(...){
...
while(...){
...
skb = tcp_write_queue_tail(sk); // 获取发送队列最后一个skb
...
// 如果发送队列的skb剩余空间小于未发送的数据量, 需要申请新skb
skb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation);
...
// 将用户空间的数据拷贝到内核空间
err = skb_add_data_nocache(sk, skb, from, copy);
...
//发送判断
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
}
...
}
}
}
struct sk_buff(常简称为skb)在Linux网络栈中表示一个网络包。它有两个主要的数据区用来存储数据,分别是线性数据区(linear data area)和分页区(paged data area)。
线性数据区(linear data area): 这个区域连续存储数据,并且能够容纳一个完整的网络包的所有协议头,比如MAC头、IP头和TCP/UDP头等。除了协议头部,线性数据区还可以包含一部分或全部的数据负载。每个skb都有一个线性数据区。分页区(paged data area): 一些情况下,为了优化内存使用和提高性能,skb的数据负载部分可以存储在一个或多个内存页中,而非线性数据区。分页区的数据通常只包含数据负载部分,不包含协议头部。如果一个skb的数据全部放入了线性数据区,那么这个skb就没有分页区。
这种设计的好处是,对于大的数据包,可以将其数据负载部分存储在分页区,避免对大块连续内存的分配,从而提高内存使用效率,减少内存碎片。另外,这种设计也可以更好地支持零拷贝技术。例如,当网络栈接收到一个大数据包时,可以直接将数据包的数据负载部分留在原始的接收缓冲区(即分页区),而无需将其拷贝到线性数据区,从而节省了内存拷贝的开销。
传输层发送
假设现在内核发送条件已经满足了,无论调用的是 __tcp_push_pending_frames 还是 tcp_push_one 最终都实际会执行到 tcp_write_xmit。所以我们直接从 tcp_write_xmit 看起,这个函数处理了传输层的拥塞控制、滑动窗口相关的工作。满足窗口要求的时候,设置一下 TCP 头然后将 skb 传到更低的网络层进行处理。
//file: net/ipv4/tcp_output.c
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp)
{
//循环获取待发送 skb
while ((skb = tcp_send_head(sk)))
{
//滑动窗口相关
cwnd_quota = tcp_cwnd_test(tp, skb);
tcp_snd_wnd_test(tp, skb, mss_now);
tcp_mss_split_point(...);
tso_fragment(sk, skb, ...);
......
//真正开启发送
tcp_transmit_skb(sk, skb, 1, gfp);
}
}
//file: net/ipv4/tcp_output.c
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask)
{
//1.克隆新 skb 出来
if (likely(clone_it)) {
skb = skb_clone(skb, gfp_mask);
......
}
//2.封装 TCP 头
th = tcp_hdr(skb);
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->window = ...;
th->urg = ...;
......
//3.调用 “网络层” 发送接口
err = icsk->icsk_af_ops->queue_xmit(skb, &inet->cork.fl);
}tcp_transmit_skb第一件事是先克隆一个新的 skb,这里重点说下为什么要复制一个 skb 出来呢?是因为 skb 后续在调用网络层,最后到达网卡发送完成的时候,这个 skb 会被释放掉。而我们知道 TCP 协议是支持丢失重传的,在收到对方的 ACK 之前,这个 skb 不能被删除。所以内核的做法就是每次调用网卡发送的时候,实际上传递出去的是 skb 的一个拷贝,等收到 ACK 再真正删除。
第二件事是修改 skb 中的 TCP header,根据实际情况把 TCP 头设置好。这里要介绍一个小技巧,skb 内部其实包含了网络协议中所有的 header。在设置 TCP 头的时候,只是把指针指向 skb 的合适位置。后面再设置 IP 头的时候,在把指针挪一挪就行,避免频繁的内存申请和拷贝,效率很高。
网络层发送处理
在网络层里主要处理路由项查找、IP 头设置、netfilter 过滤、skb 切分(大于 MTU 的话)等几项工作,处理完这些工作后会交给更下层的邻居子系统来处理。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
//检查 socket 中是否有缓存的路由表
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
//没有缓存则展开查找
//则查找路由项, 并缓存到 socket 中
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
//为 skb 设置路由表
skb_dst_set_noref(skb, &rt->dst);
//设置 IP header
iph = ip_hdr(skb);
iph->protocol = sk->sk_protocol;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->frag_off = ...;
//发送
ip_local_out(skb);
}
//file: net/ipv4/ip_output.c
int ip_local_out(struct sk_buff *skb) {
// 执行 netfilter 过滤, 如果你设置复杂的netfilter规则,在这里将会导致你的进程CPU开销会极大增加。
err = __ip_local_out(skb);
// 开始发送数据
err = dst_output(skb);
}
//file: net/ipv4/ip_output.c
static int ip_finish_output(struct sk_buff *skb)
{
//大于 mtu 的话就要进行分片了
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2);
else
return ip_finish_output2(skb);
}在 ip_finish_output 中我们看到,如果数据大于 MTU 的话,是会执行分片的。分片会带来两个问题:1、需要进行额外的切分处理,有额外性能开销。2、只要一个分片丢失,整个包都得重传。所以避免分片既杜绝了分片开销,也大大降低了重传率。
邻居子系统
邻居子系统是位于网络层和数据链路层中间的一个系统,其作用是对网络层提供一个封装,让网络层不必关心下层的地址信息,让下层来决定发送到哪个 MAC 地址。
在邻居子系统里主要是查找或者创建邻居项,在创造邻居项的时候,有可能会发出实际的 arp 请求。然后封装一下 MAC 头,将发送过程再传递到更下层的网络设备子系统。当获取到硬件 MAC 地址以后,就可以封装 skb 的 MAC 头了。最后调用 dev_queue_xmit 将 skb 传递给 Linux 网络设备子系统。
网络设备子系统
邻居子系统通过 dev_queue_xmit 进入到网络设备子系统中来。
//file: net/core/dev.c
int dev_queue_xmit(struct sk_buff *skb)
{
//选择发送队列
txq = netdev_pick_tx(dev, skb);
//获取与此队列关联的排队规则
q = rcu_dereference_bh(txq->qdisc);
//如果有队列,则调用__dev_xmit_skb 继续处理数据
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
//没有队列的是回环设备和隧道设备
......
}
注意:在网卡有多个发送队列,然后获取与此队列关联的struct Qdisc *q,这里会将skb加入到发送队列中。
然后,我们 while 循环不断地从队列中取出skb并进行发送。
//file: net/sched/sch_generic.c
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock)
{
//调用驱动程序来发送数据
ret = dev_hard_start_xmit(skb, dev, txq);
}软中断调度
如果系统态 CPU 发送网络包不够用的时候,会调用 __netif_schedule 触发一个软中断。软中断是由内核线程来运行的,该线程会进入到 net_tx_action 函数,在该函数中能获取到发送队列,并也最终调用到驱动程序里的入口函数 dev_hard_start_xmit。
static inline void __netif_reschedule(struct Qdisc *q) {}
static void net_tx_action(struct softirq_action *h) {}
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq) {}igb网卡驱动发送
网络设备子系统中的 dev_hard_start_xmit 函数,会调用到驱动里的发送函数 igb_xmit_frame。
在驱动函数里,将 skb 会挂到 RingBuffer上,驱动调用完毕后,数据包将真正从网卡发送出去。
当所有需要的描述符都已建好,且 skb 的所有数据都映射到网卡可访问的内存 DMA 区域后,驱动就会进入到它的最后一步,触发真实的发送。
发送完成硬中断
当数据发送完成以后,其实工作并没有结束。因为还没有清理内存。当发送完成的时候,网卡设备会触发一个硬中断来释放内存。在发送完成硬中断里,会执行 RingBuffer 的内存清理工作,清理skb,解除了DMA映射等等
为啥我说是基本完成,而不是全部完成了呢?因为传输层需要保证可靠性,所以 skb 其实还没有删除(传输层会复制一份skb当丢包等会利用这份skb重新发送一次)。它得等收到对方的 ACK 之后才会真正删除,那个时候才算是彻底的发送完毕。
网络数据包的接受过程
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从
网卡硬件缓存转移到服务器内存中。 - 通知内核处理。
- 经过IP协议逐层处理。
- 经过TCP/UDP协议逐层处理。
- 应用程序通过read()从socket buffer读取数据。
关键知识点:网卡收到的数据怎么写入到内核内存?
同发送数据一样,使用了关键的技术点ring buffer, sk_buffer, DMA, 中断(信号通知)
NIC(网卡)在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是ring buffer。它是由NIC和驱动程序共享的一片区域,事实上,ring buffer存储的并不是实际的packet数据,而是一个描述符(指针),这个描述符指向了它真正的存储地址(内核内存)。
- 网卡收到数据包,先将高低电平转换到网卡fifo存储,网卡申请
RingBuffer的描述,根据描述找到具体的物理地址,从fifo队列物理网卡会使用DMA将数据包写到了该物理地址(内核内存),其实就是skb_buffer中. - 这个时候数据包已经被转移到
skb_buffer中,因为是DMA写入,内核并没有监控数据包写入情况,这时候NIC(网卡)触发一个硬中断,每一个硬件中断会对应一个中断号,且指定一个CPU来处理 - 硬件中断的中断处理程序,调用驱动程序完成,启动软中断,
上述过程过程简单描述为:网卡收到数据包,DMA到内核内存,中断通知内核数据有了,内核按轮次处理消耗数据包,一轮处理完成后,开启硬中断。其核心就是网卡和内核其实是生产和消费模型,网卡生产,内核负责消费,生产者需要通知消费者消费;如果生产过快会产生丢包,如果消费过慢也会产生问题。也就说在高流量压力情况下,只有生产消费优化后,消费能力够快,此生产消费关系才可以正常维持,所以如果物理接口有丢包计数时候,未必是网卡存在问题,也可能是内核消费的太慢。
关键知识点:网卡的基础知识
每个网卡一般都有4K以上的硬件内存,用来发送和接收数据。发送数据时,数据在从主内存搬到网卡之后,先在网卡自身的内存中排队,再按照先后顺序发送。同样从网卡接收数据时,数据从以太网传递到网卡时,网卡先把数据存储到自身的内存中,等到收到一帧数据了,再经过中断的方式,告诉主CPU(不是网卡本身的微处理器)把网卡内存的数据读走,而读走后的内存,又被清空,再次被使用,用来接收新的数据,如此循环往复。
数据从网卡到内存
网卡需要有驱动才能工作,驱动是加载到内核中的模块,负责衔接网卡和内核的网络模块,驱动在加载的时候将自己注册进网络模块,当相应的网卡收到数据包时,网络模块会调用相应的驱动程序处理数据。
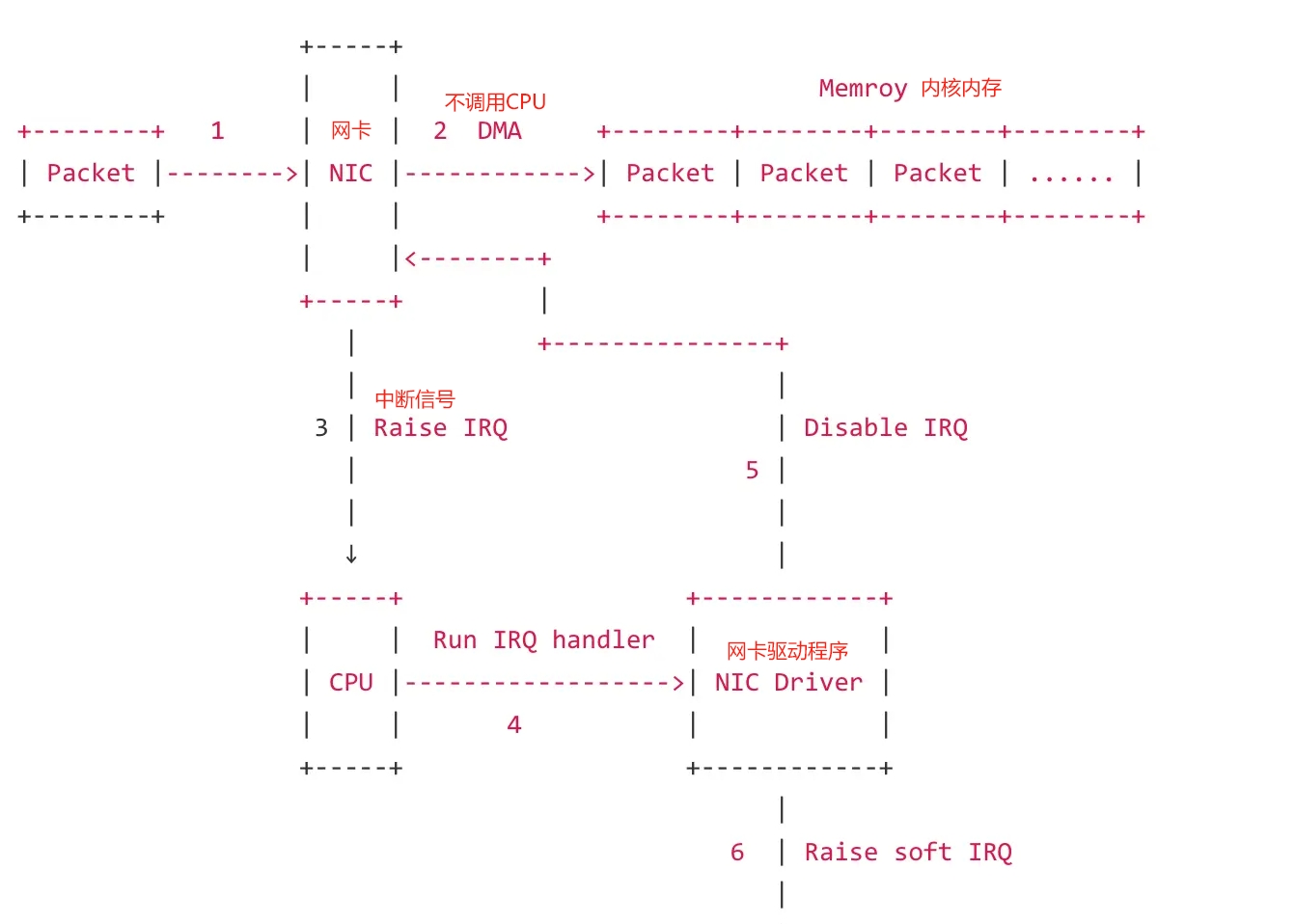
- 数据包从外面的网络进入
物理网卡。如果目的地址不是该网卡,并且该网卡没有开启混杂模式,该包会被网卡丢弃。 - 网卡将数据包通过
DMA的方式写入到指定的内核内存地址,该地址由网卡驱动分配。 - 网卡通过
硬件中断(IRQ)告知cpu有数据来了。 - cpu根据中断表,调用已经注册的
中断函数,这个中断函数会调动驱动程序中相应的函数 - 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知cpu了,这样可以提高效率,避免cpu不停的被中断
- 启动
软中断。这步结束后,硬件中断处理函数就结束返回了,由于硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致cpu无法响应其他硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
数据在内核网络模块
接上一步,软中断会触发内核网络模块中的软中断处理函数,后续流程如下
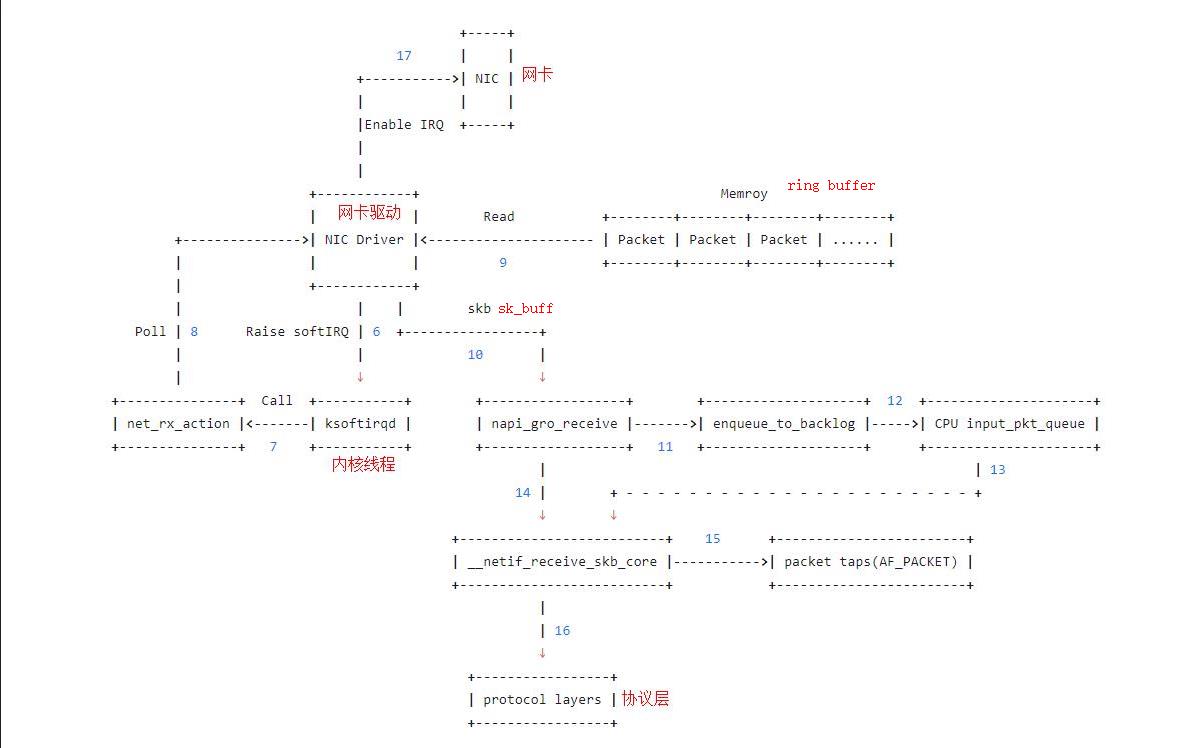
- 7: 内核中的
ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于上面第6步中是网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数 - 8:
net_rx_action调用网卡驱动里的poll函数来一个一个的处理数据包 - 9: 在
pool函数中,驱动会一个接一个的读取网卡写到内存中的数据包,内存中数据包的格式只有驱动知道 - 10: 驱动程序将内存中的数据包转换成内核网络模块能识别的
skb格式,然后调用napi_gro_receive函数 - 11:
napi_gro_receive会处理GRO相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈。然后判断是否开启了RPS,如果开启了,将会调用enqueue_to_backlog - 12: 在
enqueue_to_backlog函数中,会将数据包放入CPU的softnet_data结构体的input_pkt_queue中,然后返回,如果input_pkt_queue满了的话,该数据包将会被丢弃,queue的大小可以通过net.core.netdev_max_backlog来配置 - 13: CPU会接着在自己的软中断上下文中处理自己
input_pkt_queue里的网络数据(调用__netif_receive_skb_core) - 14: 如果没开启RPS,
napi_gro_receive会直接调用__netif_receive_skb_core - 15: 看是不是有AF_PACKET类型的socket(也就是我们常说的原始套接字),如果有的话,拷贝一份数据给它。tcpdump抓包就是抓的这里的包。
- 16: 调用协议栈相应的函数,将数据包交给协议栈处理。
- 17: 待内存中的所有数据包被处理完成后(即poll函数执行完成),启用网卡的
硬中断,这样下次网卡再收到数据的时候就会通知CPU
数据在协议栈的IP层
接上一步,由于模拟的是UDP包,所以第一步会进入IP层,然后一级一级的函数往下调:
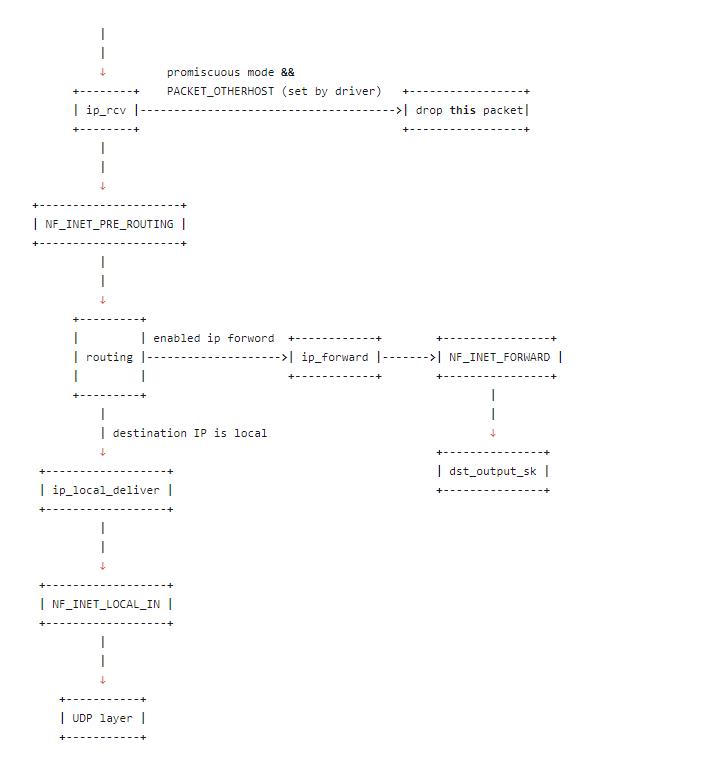
ip_rcv: ip_rcv函数是IP模块的入口函数,在该函数里面,第一件事就是将垃圾数据包(目的mac地址不是当前网卡,但由于网卡设置了混杂模式而被接收进来)直接丢掉,然后调用注册在NF_INET_PRE_ROUTING上的函数NF_INET_PRE_ROUTING:netfilter放在协议栈中的钩子(注意:这里是防火墙的基础),可以通过iptables来注入一些数据包处理函数,用来修改或者丢弃数据包,如果数据包没被丢弃,将继续往下走。routing: 进行路由,如果是目的IP不是本地IP,且没有开启ip forward功能,那么数据包将被丢弃,如果开启了ip forward功能,那将进入ip_forward函数ip_forward:ip_forward会先调用netfilter注册的NF_INET_FORWARD相关函数,如果数据包没有被丢弃,那么将继续往后调用dst_output_sk函数dst_output_sk: 该函数会调用IP层的相应函数将该数据包发送出去,同下一篇要介绍的数据包发送流程的后半部分一样。ip_local_deliver:如果上面routing的时候发现目的IP是本地IP,那么将会调用该函数,在该函数中,会先调用NF_INET_LOCAL_IN相关的钩子程序,如果通过,数据包将会向下发送到UDP层
数据在协议栈的UDP层

udp_rcv: udp_rcv函数是UDP模块的入口函数,它里面会调用其它的函数,主要是做一些必要的检查,其中一个重要的调用是__udp4_lib_lookup_skb,该函数会根据目的IP和端口找对应的socket,如果没有找到相应的socket,那么该数据包将会被丢弃,否则继续sock_queue_rcv_skb: 主要干了两件事,一是检查这个socket的receive buffer是不是满了,如果满了的话,丢弃该数据包,然后就是调用sk_filter看这个包是否是满足条件的包,如果当前socket上设置了filter,且该包不满足条件的话,这个数据包也将被丢弃(在Linux里面,每个socket上都可以像tcpdump里面一样定义filter,不满足条件的数据包将会被丢弃)__skb_queue_tail: 将数据包放入socket接收队列的末尾sk_data_ready: 通知socket数据包已经准备好
数据在应用层socket
应用层一般有两种方式接收数据,
- 一种是recvfrom函数阻塞在那里等着数据来,这种情况下当socket收到通知后,recvfrom就会被唤醒,然后读取接收队列的数据;
- 另一种是通过epoll或者select监听相应的socket,当收到通知后,再调用recvfrom函数去读取接收队列的数据。
两种情况都能正常的接收到相应的数据包。
网络数据包的传输过程
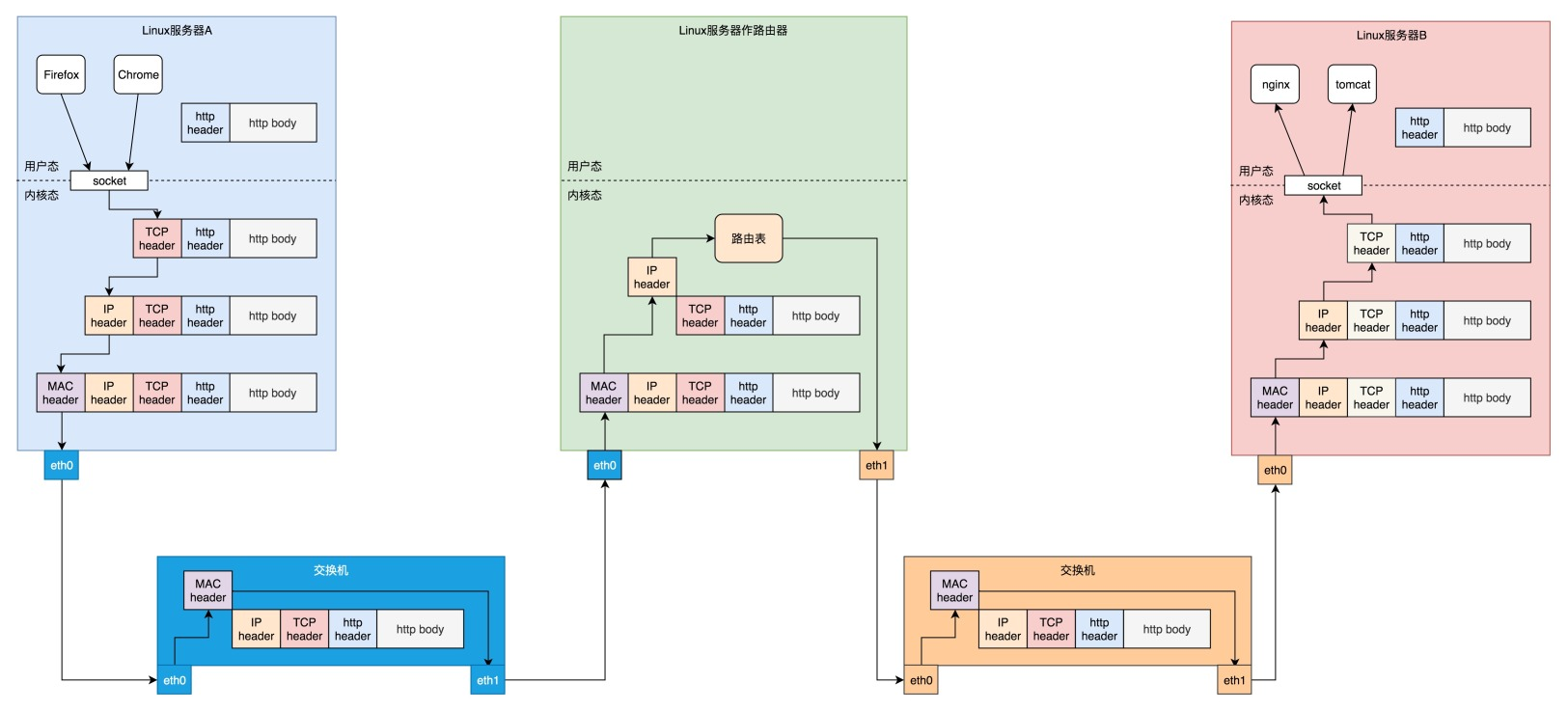
数据包的传输,主要考虑的是tcp、ip、mac地址在网络设备(网卡、路由器、交换机等)的数据封包和拆包的过程。大致可以用以下图片概况:
Socket简介
Socket: 用于描述IP地址和端口,是一个通信链的句柄,可以用来实现不同虚拟机或不同计算机之间的通信。所以Socket是对TCP/IP协议的封装,它是一组接口,它把复杂的TCP/IP协议族隐藏在Socket接口后面。
Socket是面向客户/服务器模型而设计的,针对客户和服务器程序提供不同的Socket系统调用。通过Socket建立通信连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket,另一个运行于服务器端,称为ServerSocket。
套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。
-
服务器监听:是服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态。 -
客户端请求:是指由客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。 -
连接确认:是指当服务器端套接字监听到或者说接收到客户端套接字的连接请求,它就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发给客户端,一旦客户端确认了此描述,连接就建立好了。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
Socket分类
Socket 的分类主要有三种, 这三种也是主要针对传输层协议划分的
流套接字: 使用的是传输层TCP协议, TCP 即传输控制协议, 对于字节流来说, 可以理解为传输的数据是基于 IO 流, 其主要特征就是在 IO 流没有关闭的情况下是无边界的数据, 可以多次发送, 也可以分开多次接收;
数据报套接字: 使用传输层UDP协议, UDP 即用户数据报协议, 对于数据报而言, 可以简单的理解为传输的数据是一块一块的, 例如一块数据为 100 个字节, 那么发送的这一块数据就是 100 个字节, 并且必须一次发送, 接受也必须一次接收这 100 个字节的数据, 这时候就不能分多次发送或者接收;
原始套接字: 原始套接字使用的便是自定义传输层协议, 主要用于读写内核没有处理的 IP 协议数据, 简单了解即可;
Socket中常用的方法
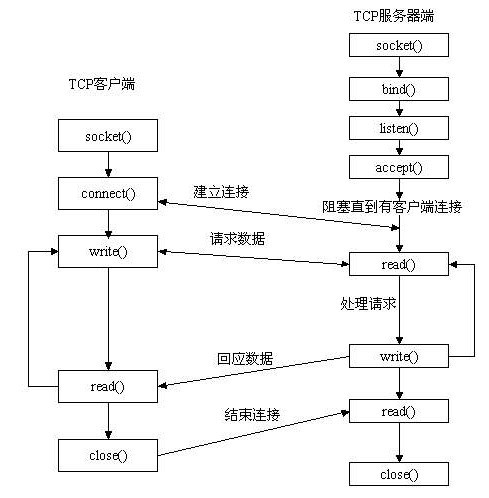
- 1.服务器先用 socket 函数来建立一个套接字,用这个套接字完成通信的监听。
- 2.用 bind 函数来绑定一个端口号和 IP 地址。因为本地计算机可能有多个网址和 IP,每一个 IP 和端口有多个端口。需要指定一个 IP 和端口进行监听。
- 3.服务器调用 listen 函数,使服务器的这个端口和 IP 处于监听状态,等待客户机的连接。
- 4.客户机用 socket 函数建立一个套接字,设定远程 IP 和端口。
- 5.客户机调用 connect 函数连接远程计算机指定的端口。
- 6.服务器用 accept 函数来接受远程计算机的连接,建立起与客户机之间的通信。
- 7.建立连接以后,客户机用 write 函数向 socket 中写入数据。也可以用 read 函数读取服务器发送来的数据。
- 8.服务器用 read 函数读取客户机发送来的数据,也可以用 write 函数来发送数据。
- 9.完成通信以后,用 close 函数关闭 socket 连接。
RDMA与Socket通信比较
几种DMA介绍
DMA(Direct Memory Access):
DMA是一种计算机系统中的数据传输技术,旨在通过绕过CPU直接将数据从外设(例如硬盘驱动器)复制到内存或从内存复制到外设,以提高数据传输的效率。在DMA中,数据通过系统总线直接传输,而不需要CPU进行每个数据字节的读取和写入操作。这样可以减轻CPU的负担,并提高数据传输的速度。
SG-DMA(Scatter-Gather DMA):
SG-DMA是DMA的一种变体,它允许数据在内存中非连续地分散存储(散列),同时在传输过程中可以将这些分散的数据聚集起来。具体来说,SG-DMA通过描述符表(Descriptor Table)来指定多个散列内存区域,这样可以在单个DMA传输中处理多个散列数据。因此,SG-DMA适用于处理非连续和分段存储的数据,例如网络数据包或媒体数据流。
RDMA(Remote Direct Memory Access):
RDMA是一种用于远程数据传输的技术,它允许两台计算机之间直接进行内存访问,而无需CPU的干预。传统的网络数据传输需要CPU从发送端将数据读取到内存,然后再由CPU将数据写入接收端的内存。而RDMA则通过绕过CPU,使得两个计算机之间可以直接进行内存读写操作,从而加速数据传输并降低CPU的负载。RDMA常用于高性能计算、云计算和分布式存储等领域。
扩展阅读
Linux·图解网络包发送过程
深入理解Linux网络——内核是如何发送网络包的
Linux·图解网络包接收过程
网络数据包接收流程
struct sk_buff结构体详解
Linux内核:sk_buff解析
Socket 套接字详细介绍及套接字通信流程和编程的具体实现
计算机网络:Socket网络通信底层数据传输
网络通信的核心机制:Socket如何实现高效数据传输
比较基于传统以太网与RDMA技术的通信
图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!
最后更新于 2024-01-23 01:27:43 并被添加「」标签,已有 2698 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭